[Webinar] From Fire Drills to Zero-Loss Resilience | Register Now
What Is Batch Processing?
Batch processing refers to the execution of batch jobs, where data is collected, stored, and processed at scheduled intervals—often in off-peak times of the day. For decades, batch processing has given organizations an efficient and scalable way to process large volumes of data in predefined batches or groups.
Let's dive into how batch processing works so you can understand the best times to use it and when to combine it with real-time streaming solutions like the Confluent data streaming platform.
Historically, this approach to handling data has enabled numerous operational and analytics use cases across various industries. Today, however, batch-based business functions like financial transactions, data analytics, and report generation frequently require much faster insights from the underlying data. The increasing demand for near real-time and real-time data processing, has led to the rise of data processing technologies like Apache Kafka® and Apache Flink®.
An Overview – Batch Processing Challenges & How We Got Here
Batch processing has long been the default approach for moving and transforming data in enterprise systems due to its efficiency in handling large volumes of data. Processing data in batches allowed large businesses to manage and analyze data without overloading their systems, offering a predictable, cost-effective solution for tasks like payroll, inventory management, or financial reporting.
However, today’s digital businesses operate in real time—and can’t afford to wait hours for fresh insights. As technology evolves and the demand for real-time insights grows, the limitations of batch processing have become evident, giving rise to data streaming and stream processing as more agile alternatives.
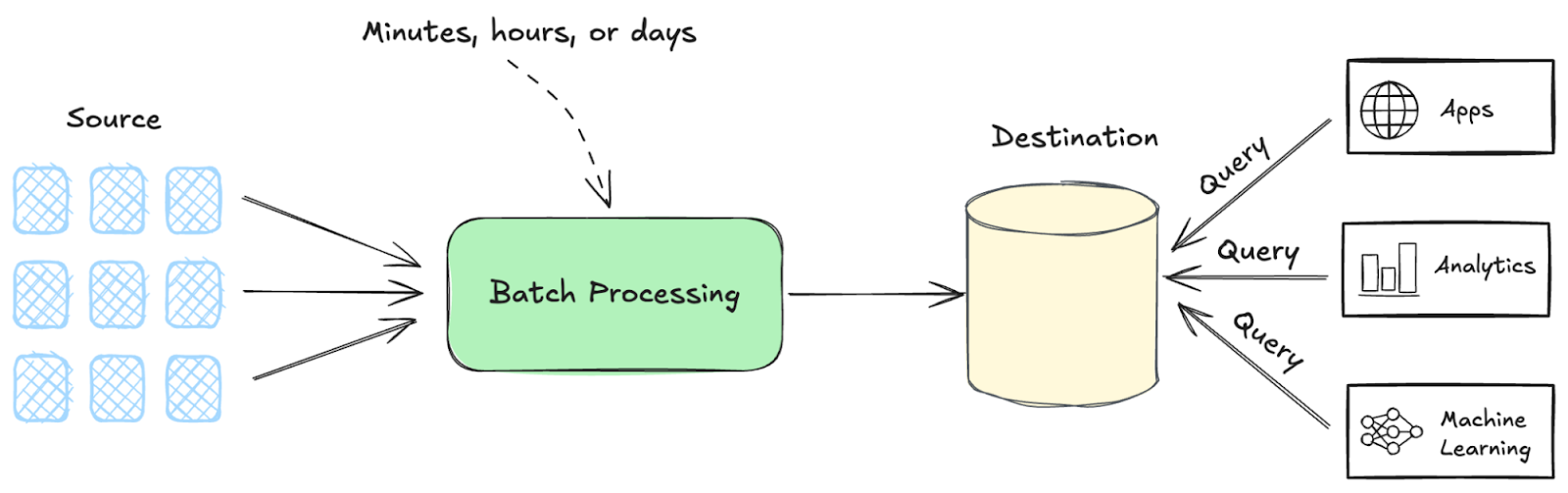
How Batch Processing Works
While batch processing applications can vary based on the task at hand, here’s an overview of how it works:
- Data Collection: Data is collected over time from various sources and stored until ready for processing
- Batch Execution: A batch job is triggered based on a schedule (eg., nightly) or a defined data threshold
- Output Generation: The results after the batch execution are generated in various forms, including reports and database updates.
To implement batch processing effectively, organizations rely on dedicated software and systems that streamline data ingestion, processing, and output generation. Examples of batch processing include extract-transform-load (ETL) processes, daily backups, and large-scale data transformations.
Common Batch Processing Challenges
While batch processing has powered data pipelines for decades, it introduces a range of problems that make it increasingly unfit for today’s real-time, scalable, and reliable data needs, including:
-
Thousands of batch jobs and complexity
-
High latency and outdated information
-
Missing data and data inconsistencies
-
Brittle pipelines and manual fixes
-
Compliance challenges
-
Inaccurate data
See how batch processing was holding back Globe Group back from driving personalized marketing campaigns.
From Batch Processing to Micro-Batches to Data Streaming
From early days of computing, data has always been stored and processed in batches even when it was generated in a stream. This is largely due to technical limitations in data collection, storage, and processing. Over a period of decades, those technical limitations lessened and the cost of storage, compute and networking came down by orders of magnitude. This allowed for the rise of low-cost distributed systems like Apache Hadoop®, which was an early leader in handling large-scale batch processing but often struggled with speed and complexity.
Later, Apache Spark™ emerged as a faster, more flexible alternative, offering in-memory processing that dramatically reduced job execution times, making it suitable for both batch and micro-batch workloads. However, as the demand for real-time data and continuous processing increased, Apache Kafka® was developed at LinkedIn and then open-sourced. Its distributed architecture made it ideal for realizing the high throughput, low latency, and fault tolerance needed for real-time, high-throughput, and low-latency use cases.
Key Differences Between Batch and Stream Processing
Batch processing and stream processing differ primarily in the following areas:
-
Data Handling: Batch processing involves collecting and storing data over a period of time, then processing it in large batches at scheduled intervals. On the other hand, using stream processing pipelines built with technologies like Kafka and Flink transform and enrich your data as it's generated, allowing for immediate insights and actions.
-
Latency: Because batch processing involves processing data in bulk, using it incurs higher latency between data generation and processing a delay which may range from hours to days. Stream processing offers low latency, providing near-instantaneous processing and analysis of data as it arrives. See how L'Oréal powered digital transformation after transitioning away from batch processing.
-
Use Cases: Batch processing is ideal for tasks like end-of-day reporting or data warehousing, where immediate processing isn’t critical. Stream processing is suited for event-driven applications and real-time use cases that require real-time analytics, such as fraud detection, recommendation systems, or monitoring of sensor data.
-
Complexity: Batch processing is generally simpler to implement and more cost-effective for large-scale data tasks, while stream processing often involves more complex architectures to manage the continuous flow of data and maintain real-time performance.
Benefits of Real-Time vs Batch Processing
Batch processing is widely used across industries—especially in scenarios where large volumes of data need to be processed during off-peak hours. Here are a few use cases:
-
End-of-day reporting: Financial institutions rely on batch processing to compile and process transactions accumulated throughout the day. This enables the generation of comprehensive reports used for compliance, auditing, and performance analysis.
-
Payroll processing: Organizations handle payroll in batches—by collecting employee hours, calculating compensation, and issuing payments in one streamlined process.
-
Data warehouse updates: Batch processing is commonly used to refresh data warehouses at scheduled intervals.
But as real-time data becomes more important than ever, businesses across industries are modernizing their data infrastructure to react faster, reduce complexity, and deliver better outcomes. In fact, according to the 2025 Data Streaming Report, 86% of IT leaders cite investments in data streaming as a key priority. Additionally, 44% of IT leaders also cite 5x or more ROI with real-time data streaming while driving significant benefits in the areas of customer experience (95%), security and risk management (92%), product/service innovation (90%), and reduced time to market (86%).
With data streaming, instead of waiting until the end of the day, financial institutions can process transactions as they happen, enabling real-time visibility into account activity, risk, and compliance metrics. Benefits include immediate detection of anomalies and fraud, and faster decision-making and customer response. When it comes to data warehousing updates, data streaming allows for data to be continuously ingested, transformed, and delivered to analytics platforms in real time, removing the need for scheduled ETL jobs.
A data streaming platform like Confluent takes it further by helping move data processing, governance, and quality checks closer to the source of data creation—a process known as shifting left—rather than waiting until the data reaches the data warehouse. This reduces data quality issues by up to 60%, decreases compute costs by 30%, and improves engineering productivity.
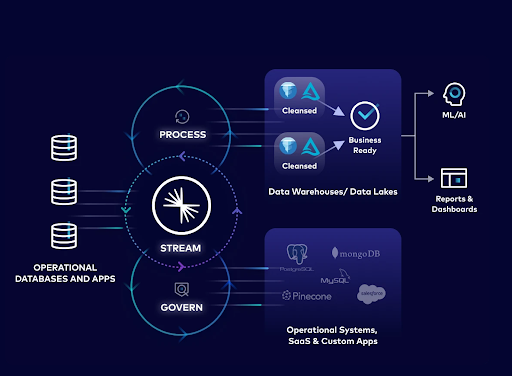
The right data streaming platform can help your organization move data across data systems, govern and process it to build data products, and future-proof your data architecture.
Batch Processing vs. Data Streaming vs. Stream Processing
|
Feature |
Batch Processing |
||
|
Data Processing |
Data is processed in batches at designated intervals |
Data is ingested and integrated continuously in real or near-real time |
Data is processed and analyzed as it is received |
|
Data Volume |
Large amounts of data |
High-volume data |
Small amounts of data |
|
Data Latency |
High latency |
Low latency |
Low latency |
|
Cost |
Low cost scaling, high cost due to duplicate processing and manual break-fix work |
Cost-effective with the right architecture |
Cost-effective with shift-left processing and governance |
|
Use Cases |
Data consolidation, data analysis, data mining, data backup and recovery |
Personalized recommendations, real-time fraud detection, real-time stock trades, predictive analytics |
Real-time analytics, fraud detection, anomaly detection |
How to Know If Batch Is Right for Your Use Cases
Historically, batch processing is a good choice for applications that do not require immediate feedback or response, such as data consolidation, data analysis, data mining, and data backup and recovery.
When Batch Processing Is the Best Choice
-
When business processes are batch-aligned: Many enterprise workflows, like end of day processing or scheduled reconciliations, are naturally suited to batch
-
When integrating legacy systems: Works well with systems not built for real-time data exchange, allowing smooth data consolidation and migration
-
For analyzing historical performance: Batch processing can be used to mine data for hidden patterns and insights
-
For data backup and recovery: Batch processing can be used to back up data regularly. This can help businesses to protect their data from loss or corruption
Considerations Choosing Between Batch Processing vs Stream Processing
-
Timeliness of insights: If your business needs real-time visibility—such as fraud detection or clickstream data—stream processing offers immediate actionability. Batch processing is better suited for non-urgent tasks like monthly reporting.
-
Cost vs. responsiveness: Batch processing is typically less expensive than real-time processing. This is largely because latency is less of a concern for batch jobs. Stream processing can drive faster decisions and better customer experiences but may require greater investments in tooling and resources.
-
Operational complexity: Stream processing requires always-on infrastructure and skilled teams to manage real-time data pipelines. Batch processing is easier to implement and maintain, especially for organizations with established, time-based workflows.
-
Scalability and flexibility: Stream processing is built for continuous, high-throughput data and scales dynamically with data volume and velocity. Batch systems can handle large volumes too, but often struggle with real-time demands or sudden data spikes.
-
Use case fit: Choose based on the nature of the workload. For example, a telecom provider might use batch processing for monthly billing cycles, while using stream processing to monitor network performance and alert customers in real time when service issues arise.
When to Choose Real-Time Data Streaming and Stream Processing
The utility of batch processing has always been limited by how much time you can afford to wait. Specifically, the time it takes to process a batch and the interval between scheduled batch runs. When low-latency responses are critical, it's time to choose data processing. Here are some use cases that indicate the need for data streaming and stream processing:
-
You need instant insights or actions: For use cases like fraud detection or in-the-moment personalization
-
Customer experience depends on responsiveness: Real-time data powers dynamic pricing, recommendation engines, and real-time support
-
Delays create risk or lost revenue: In sectors like finance, logistics, and retail, real-time decisions can prevent loss or drive faster conversions
-
Data is continuously generated: Ideal for IoT, app telemetry, website interactions, or machine data where events never stop
-
You want always-on analytics: Power dashboards, alerts, and performance metrics without waiting for batch jobs
-
You’re training AI/ML models on live data: Real-time streaming enables continuous learning and faster model refinement. See why 89% of IT leaders see data streaming platforms easing AI adoption by helping them directly address hurdles in the areas of data access, quality assurance, and governance.
-
Operations need immediate visibility: For supply chain tracking, network monitoring, or anomaly detection, stream processing provides real-time situational awareness
Data streaming accelerates time to market by enabling real-time data flows that power responsive, intelligent applications. See how a complete data streaming platform helped Citizens Bank transform its operations and customer experience.
How Can Confluent Help?
Making the most of your data doesn’t have to be complicated, expensive, and risky. With Confluent, you can manage data as a product, making it instantly accessible, usable and valuable for any use case.
By empowering users to stream, connect, govern, and process data continuously in real time, Confluent enables businesses to realize the vision of AI, bring new applications to market faster, deliver exceptional customer experiences, and simplify data-driven back-end operations.
See why companies like Michelin, Notion, and Instacart trust Confluent.
Frequently Asked Questions About Transitioning From Batch to Real Time
What are the first steps to move from batch to real-time data streaming?
Start by identifying high-impact areas where real-time insights could drive value—such as customer experience, fraud detection, or operational improvements. From there assess your current data architecture and prioritize building real-time data pipelines for those use cases.
How do you identify which use cases are best suited for real-time processing?
Focus on use cases where immediacy drives business value, such as personalized recommendations or real-time analytics. Look for signs like delayed decisions, customer wait times, or missed revenue opportunities due to lagging data.
What tools and platforms support both batch and streaming during the transition?
A data streaming platform like Confluent offers support for both batch and streaming workloads—making it easier to modernize without a full rebuild. Using the Confluent data streaming platform allows you to unify your batch processing, data streaming, and stream processing workloads. Ready to explore?