[Virtual Event] Agentic AI Streamposium: Learn to Build Real-Time AI Agents & Apps | Register
The Simplest Useful Kafka Connect Data Pipeline in the World…or Thereabouts – Part 2
In the previous article in this blog series I showed how easy it is to stream data out of a database into Apache Kafka®, using the Kafka Connect API. I used MySQL in my example, but it’s equally applicable to any other database that supports JDBC—which is pretty much all of them! Now we’ll take a look at how we can stream data, such as that brought in from a database, out of Kafka and into Elasticsearch.
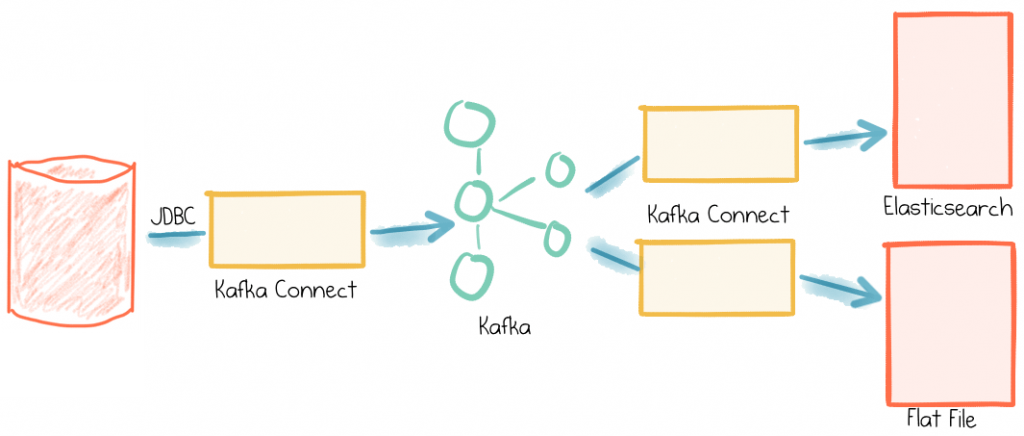
Again, we’re using Kafka Connect to do this in a scalable, fault-tolerant way, and all with just some simple configuration files!
Here I’m assuming you’ve followed the previous article for the general setup and installation steps. If you haven’t already, start Elasticsearch:
$ elasticsearch [...] [2017-08-01T15:22:40,132][INFO ][o.e.h.n.Netty4HttpServerTransport] [-1Kfx0p] publish_address {127.0.0.1:9201}, bound_addresses {[fe80::1]:9201}, {[::1]:9201}, {127.0.0.1:9201}, {127.94.0.2:9201}, {127.94.0.1:9201} [2017-08-01T15:22:40,132][INFO ][o.e.n.Node ] [-1Kfx0p] started
Now with further ado, let’s dive in!
Whilst Kafka Connect is part of Apache Kafka itself, if you want to stream data from Kafka to Elasticsearch you’ll want the Confluent Platform (or at least, the Elasticsearch connector).
The configuration is pretty simple. As before, see inline comments for details
It’s worth noting that if you’re using the same convertor throughout your pipelines (Avro, in this case) you’d actually put this in the Connect worker config itself rather than repeating it for each connector configuration.
Load the connector using the Confluent CLI:
./bin/confluent load es-sink-mysql-foobar-01 -d /tmp/kafka-connect-elasticsearch-sink.json
As with the File sink above, as soon as the connector is created and starts running (give it a few seconds to spin up; wait until the Task status is RUNNING) it will load the existing contents of the topic into the specified Elasticsearch index. In the Elasticsearch console you’ll see
[2017-07-10T13:43:27,164][INFO ][o.e.c.m.MetaDataCreateIndexService] [lGXYRzd] [mysql-foobar] creating index, cause [api], templates [], shards [5]/[1], mappings [] [2017-07-10T13:43:27,276][INFO ][o.e.c.m.MetaDataMappingService] [lGXYRzd] [mysql-foo/7lXMoHxWT6yIvmxIBlMB9A] create_mapping [type.name=kafka-connect]
Querying the data using the Elasticsearch REST API shows that the data is being streamed to it from Kafka:
$ curl -s "http://localhost:9200/mysql-foobar/_search"|jq '.hits'
{
"total": 5,
"max_score": 1,
"hits": [
{
"_index": "mysql-foobar",
"_type": "type.name=kafka-connect",
"_id": "mysql-foobar+0+4",
"_score": 1,
"_source": {
"c1": 4,
"c2": "bar",
"create_ts": 1501797647000,
"update_ts": 1501797647000
}
},
[...]
The eagle-eyed amongst you will notice that the _id of the document has been set by Kafka Connect to the topic/partition/offset, which gives us exactly-once delivery courtesy of Elasticsearch’s idempotent writes. Now, this is very useful if we just have a stream of events, but in some cases we want to declare our own key—more on this later.
We can also see that mapping has been created, using the schema of the source MySQL table – another great reason for using the Confluent Schema Registry.
$ curl -s "http://localhost:9200/mysql-foobar/_mappings"|jq '.'
{
"mysql-foobar": {
"mappings": {
"type.name=kafka-connect": {
"properties": {
"c1": {
"type": "integer"
},
"c2": {
"type": "text"
},
"create_ts": {
"type": "date"
},
"update_ts": {
"type": "date"
}
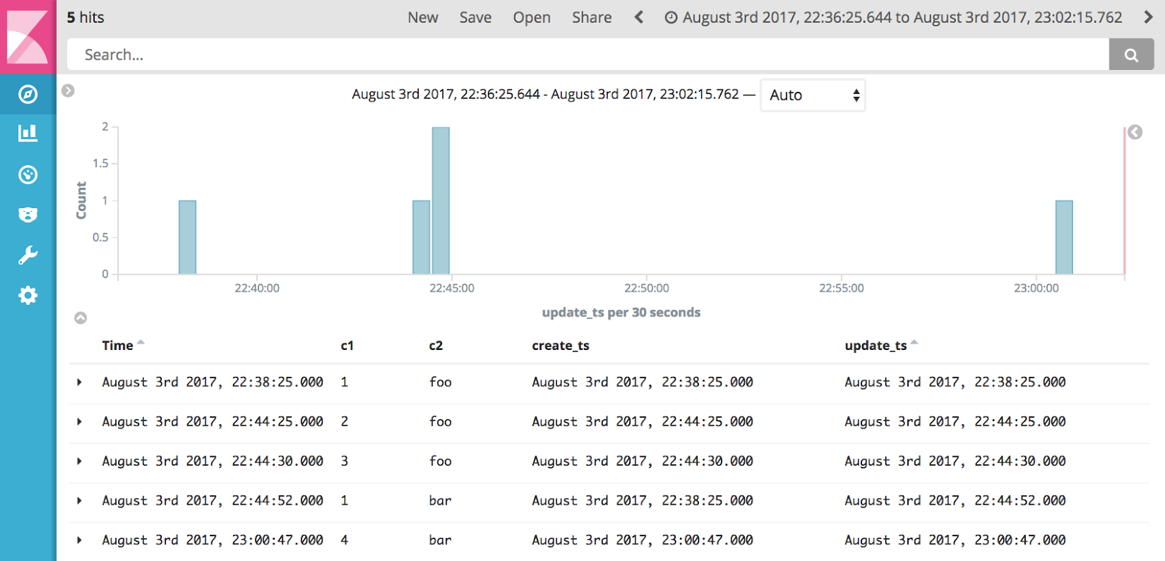
Using Kibana we can easily see the actual data that’s flowing through from Kafka, with the datatypes preserved and thus the timestamps available for selecting and aggregating our data as we want:
Recap
With a few simple REST calls, we’ve built a scalable data pipeline, streaming data from a relational database through to Elasticsearch, and a flat file. With the Kafka Connect ecosystem we could extend and modify that pipeline to land data to HDFS, BigQuery, S3, Couchbase, MongoDB … the list goes on and on!
Stay tuned for more posts in this series that will take a look at some of the additional cool features available to us in Apache Kafka and Confluent Platform.
Other Posts in this Series:
Part 1: The Simplest Useful Kafka Connect Data Pipeline In The World … or Thereabouts – Part 1
Part 3: The Simplest Useful Kafka Connect Data Pipeline in the World…or Thereabouts – Part 3
Avez-vous aimé cet article de blog ? Partagez-le !
Abonnez-vous au blog Confluent



From Dumb Pipes to a Smart Data Plane: Introducing Schema IDs in Apache Kafka® Headers
Confluent’s Schema IDs in headers transform Kafka from "dumb pipes" to a "smart data plane." By moving metadata out of payloads, teams can schematize topics without breaking legacy apps or requiring big-bang migrations. This unlocks governed, AI-ready data for Flink and lakehouses with ease.


Queues for Apache Kafka® Is Here: Your Guide to Getting Started in Confluent
Confluent announces the General Availability of Queues for Kafka on Confluent Cloud and Confluent Platform with Apache Kafka 4.2. This production-ready feature brings native queue semantics to Kafka through KIP-932, enabling organizations to consolidate streaming and queuing infrastructure while...