[Virtual Event] Agentic AI Streamposium: Learn to Build Real-Time AI Agents & Apps | Register
Streaming Machine Learning with Tiered Storage and Without a Data Lake
The combination of streaming machine learning (ML) and Confluent Tiered Storage enables you to build one scalable, reliable, but also simple infrastructure for all machine learning tasks using the Apache Kafka® ecosystem and Confluent Platform. This blog post features a predictive maintenance use case within a connected car infrastructure, but the discussed components and architecture are helpful in any industry.
The Apache Kafka ecosystem is used more and more to build scalable and reliable machine learning infrastructure for data ingestion, preprocessing, model training, real-time predictions and monitoring. I had previously discussed example use cases and architectures that leverage Apache Kafka and machine learning. Here’s a recap of what this looks like:
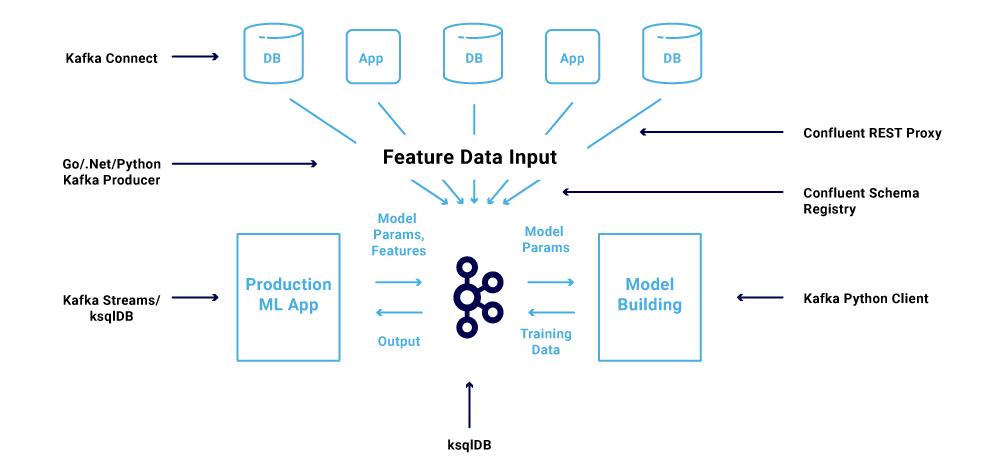
There have since been two new cutting-edge developments to Kafka, Confluent Platform, and the machine learning ecosystem:
- Streaming machine learning without the need for a data lake such as Apache™ Hadoop® or Amazon S3
- Tiered Storage for long-term storage of event streams in Confluent Platform
Both are impressive on their own. When combined, they simplify the design of mission-critical, real-time architecture, and make machine learning infrastructure more usable for data science and analytics teams.
The old way: Kafka as an ingestion layer into a data lake
A data lake is a system or repository of data stored in its natural/raw format—usually object blobs or files. It is typically a single store of all enterprise data, including raw copies of source system data and transformed data used for tasks such as reporting, visualization, advanced analytics, and machine learning. Commonly used technologies for data storage are the Hadoop Distributed File System (HDFS), Amazon S3, Google Cloud Storage (GCS), or Azure Blob Storage, as well as tools like Apache Hive™, Apache Spark™, and TensorFlow for data processing and analytics. Data processing happens in batch mode with the data stored at rest and can take minutes or even hours.
Apache Kafka is an event streaming platform that collects, stores, and processes streams of data (events) in real time and in an elastic, scalable, and fault-tolerant manner. The Kafka broker stores the data immutably in a distributed, highly available infrastructure. Consumers read the events and process the data in real time.
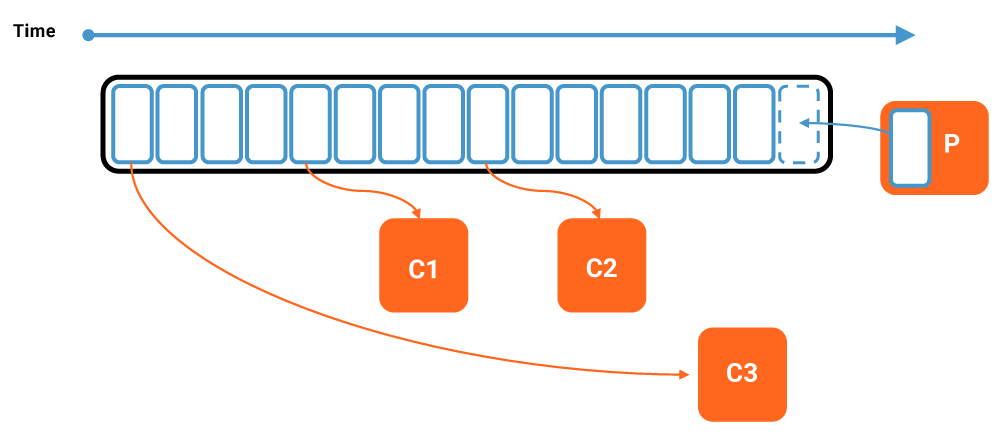
A very common pattern for building machine learning infrastructure is to ingest data via Kafka into a data lake.
From there, a machine learning framework like TensorFlow, H2O, or Spark MLlib uses the historical data to train analytic models with algorithms like decision trees, clustering, or neural networks. The analytic model is then deployed into a model server or any other application for predictions on new events in batch or in real time.
All processing and machine-learning-related tasks are implemented in the analytics platform. While the ingest happens in (near) real time via Kafka, all other processing is typically done in batch. The problem with a data lake as a central storage system is its batch nature. If the core system is batch, you cannot add real-time processing on top of it. This means you lose most of the benefits of Kafka’s immutable log and offsets and instead now end up having to manage two different systems with different access patterns.
Another drawback of this traditional approach is using a data lake just for the sake of storing the data. This adds additional costs and operational efforts for the overall architecture. You should always ask yourself: do I need an additional data lake if I have the data in Kafka already? What are the advantages and use cases? Do I need a central data lake for all business units, or does just one business unit need a data lake? If so, is it for all or just some of the data?
Unsurprisingly, more and more enterprises are moving away from one central data lake to use the right datastore for their needs and business units. Yes, some people still need a data lake (for their relevant data, not all enterprise data). But others actually need something different: a text search, a time series database, or a real-time consumer to process the data with their business application.
The new way: Kafka for streaming machine learning without a data lake
Let’s take a look at a new approach for model training and predictions that do not require a data lake. Instead, streaming machine learning is used: direct consumption of data streams from Confluent Platform into the machine learning framework.
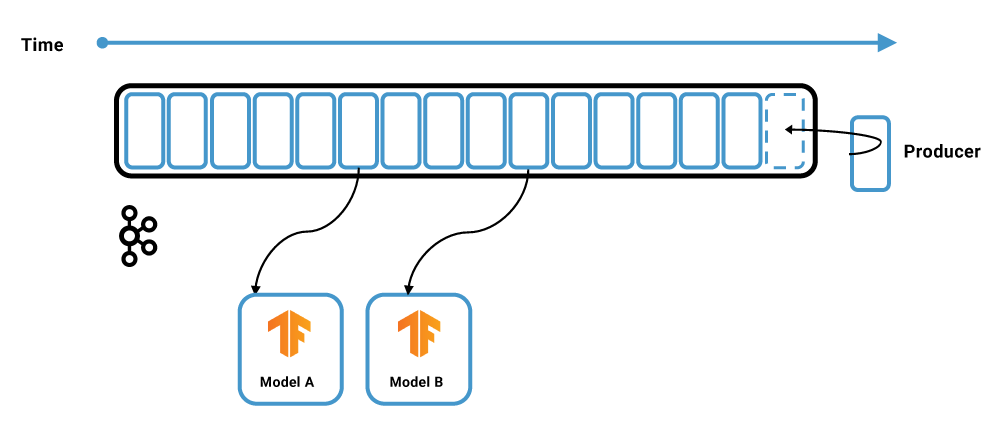
This example features the TensorFlow I/O and its Kafka plugin. The TensorFlow instance acts as a Kafka consumer to load new events into its memory. Consumption can happen in different ways:
- In real time directly from the page cache: not from disks attached to the broker
- Retroactively from the disks: this could be either all data in a Kafka topic, a specific time span, or specific partitions
- Falling behind: even if the goal might always be real-time consumption, the consumer might fall behind and need to consume “old data” from the disks. Kafka handles the backpressure
Most machine learning algorithms don’t support online model training today, but there are some exceptions like unsupervised online clustering. Therefore, the TensorFlow application typically takes a batch of the consumed events at once to train an analytic model.
The main difference between the new and the old way is that no additional data storage like HDFS or S3 is required as an intermediary in the new way.
For example, this Python example implements image recognition for numbers with TensorFlow I/O and Kafka using the MNIST dataset:
Kafka is used as a data lake and single source of truth for all events in this example. This means that the core system stores all information in an event-based manner instead of using data storage at rest (like HDFS or S3). Because the data is stored as events, you can add different consumers—real time, near real time, batch, and request-response—and still use different systems and access patterns without losing the advantages of using Kafka as a data lake. If the core system were a traditional data lake, however, it would be stored at rest, and you would not be able to connect with a real time consumer.
With streaming machine learning, you can directly use streaming data for model training and predictions either in the same application or separately in different applications. Separation of concerns is a best practice and allows you to choose the right technologies for each task. In the following example, we use Python, the beloved programming language of the data scientist, for model training, and a robust and scalable Java application for real-time model predictions.
The whole pipeline is built on an event streaming platform in independent microservices. This includes data integration, preprocessing, model training, real-time predictions, and monitoring: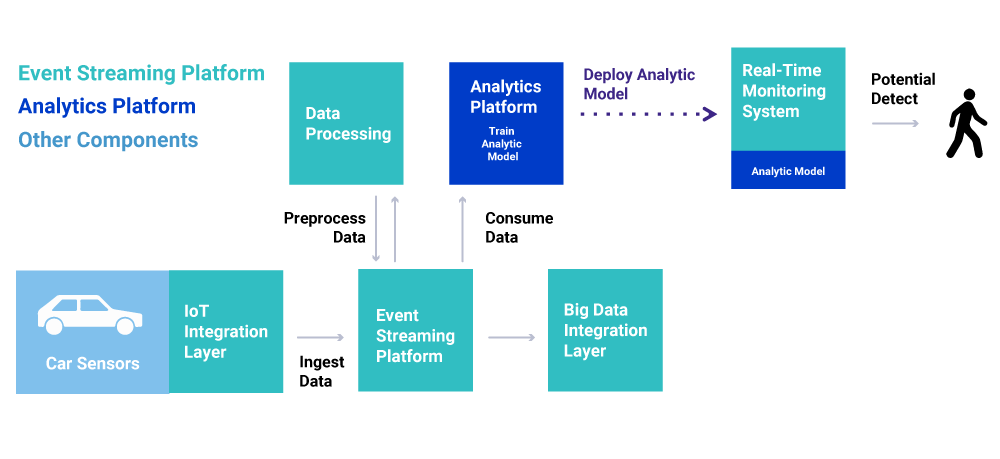
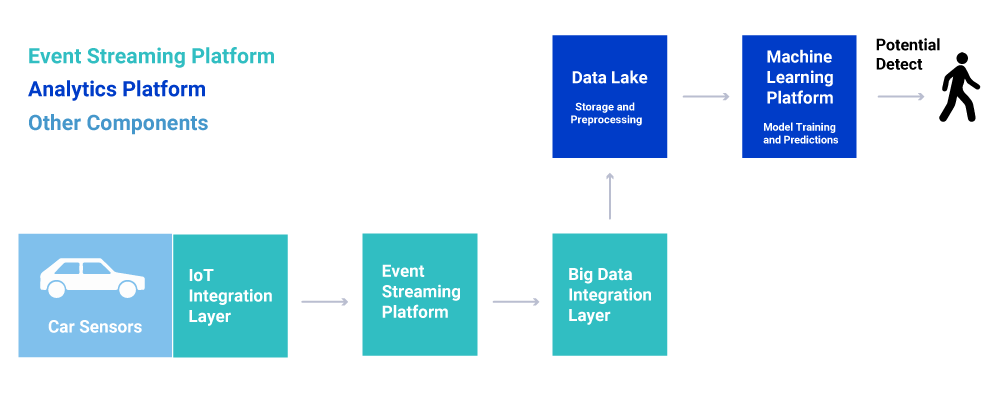
Streaming machine learning at scale with the Internet of Things (IoT), Kafka, and TensorFlow
Looking at a real-world example, we built a demo showing how to integrate with tens or even hundreds of thousands of IoT devices and process the data in real time. The use case is predictive maintenance (i.e., anomaly detection) in a connected car infrastructure to predict motor engine failures in real time, leveraging Confluent Platform and TensorFlow (including TensorFlow I/O and its Kafka plugin). MQTT Proxy is implemented with HiveMQ, a scalable and reliable MQTT cluster.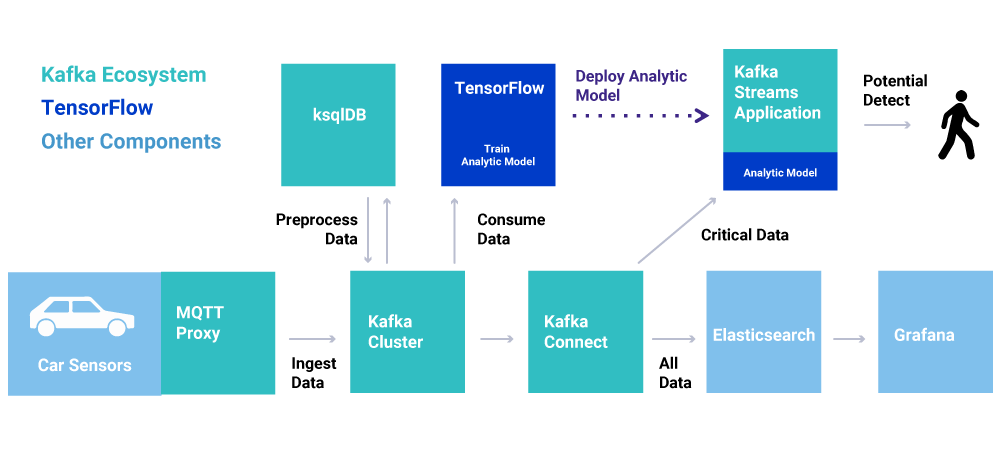 Any other Kafka application can consume the data too, including a time series database, frontend application, or batch analytics tools like Hadoop and Spark.
Any other Kafka application can consume the data too, including a time series database, frontend application, or batch analytics tools like Hadoop and Spark.
This demo, Streaming Machine Learning at Scale from 100,000 IoT Devices with HiveMQ, Apache Kafka, and TensorFlow, is available on GitHub. The project is built on Google Cloud Platform (GCP) leveraging Google Kubernetes Engine (GKE) and Terraform. Feel free to try it out and share your feedback via a pull request.
Kafka is not a data lake, right?
So far, so good. We’ve learned that we can train and deploy analytic models without the overhead of a data lake by streaming data directly into the machine learning instance(s); this simplifies the architecture and significantly reduces efforts. However, this is not to say that you should never ever build a data lake, as there are always trade-offs to consider.
Perhaps you are wondering: is it OK to use Kafka for long-term data storage?
The answer is yes! More and more people use Kafka for this purpose or even as their permanent system of record. In this example, Kafka is configured to store events for months, years, or even forever. The New York Times stores all published articles in Kafka forever as their single source of truth. You can learn more in Jay Kreps’ blog post explaining why it’s OK to store data in Kafka.
Storing data long-term in Kafka allows you to easily implement use cases in which you’d want to process data in an event-based order again:
- Replacement/migration from an old to a new application for the same use case; for example, The New York Times can create a completely new website simply by making the desired design changes (like CSS) and then reprocessing all their articles in Kafka again for re-publishing under the new style
- Reprocessing data for compliance and regulatory reasons
- Adding a new business application/microservice that is interested in some older data; for instance, this could be all events for one specific ID or all data from the very first event
- Reporting and analysis of specific time frames for parts of the data using traditional business intelligence (BI) tools
- Big data analytics for correlating historical data using machine learning algorithms to find insights that shape predictions
Modern architecture design patterns like event sourcing and CQRS leverage Kafka as event-driven backend infrastructure because it provides the required infrastructure for these architectures out of the box.
If you need to store big amounts of data, say terabytes or even petabytes, you might be thinking that long-term storage in Kafka is not practicable because of several reasons:
- Expensive storage: cost increases quickly with the more data you store on normal HDDs or SDDs. Cloud object stores like S3, GCS, and Azure Blob Storage, or object stores for on-premises infrastructures and private clouds like Ceph or MinIO are much cheaper for long-term storage.
- Risky scalability: crashes of a Kafka broker or its disk require rebalancing. The more data you have, the longer rebalancing takes. For terabytes of data, disaster recovery and rebalancing can take hours.
- Complex operations: operating a Kafka cluster is much more effort, as it involves setting up robust monitoring and alerting infrastructure.
The workaround I have seen with several customers is to build your own pipeline:
- Ingest events into the Kafka log for real-time processing and short-term storage
- Send data to a long-term storage like HDFS or S3, typically via Kafka Connect
- Bring data back into the Kafka log from where it is being stored long-term, typically via Kafka Connect
- Reprocess the historical data, e.g., for reporting or model training on historical data
For companies that build complex, expensive architectures combining an event streaming platform with a data lake for the benefits of event-based patterns and long-term data storage—how can we make this easier and cheaper? How can we get all the benefits of the immutable log and use Kafka as the single source of truth for all events, including real-time consumers, batch consumers, analytics, and request-response communication?
Confluent Tiered Storage
At a high level, the idea is very simple: Tiered Storage in Confluent Platform combines local Kafka storage with a remote storage layer. The feature moves bytes from one tier of storage to another. When using Tiered Storage, the majority of the data is offloaded to the remote store.
Here is a picture showing the separation between local and remote storage:
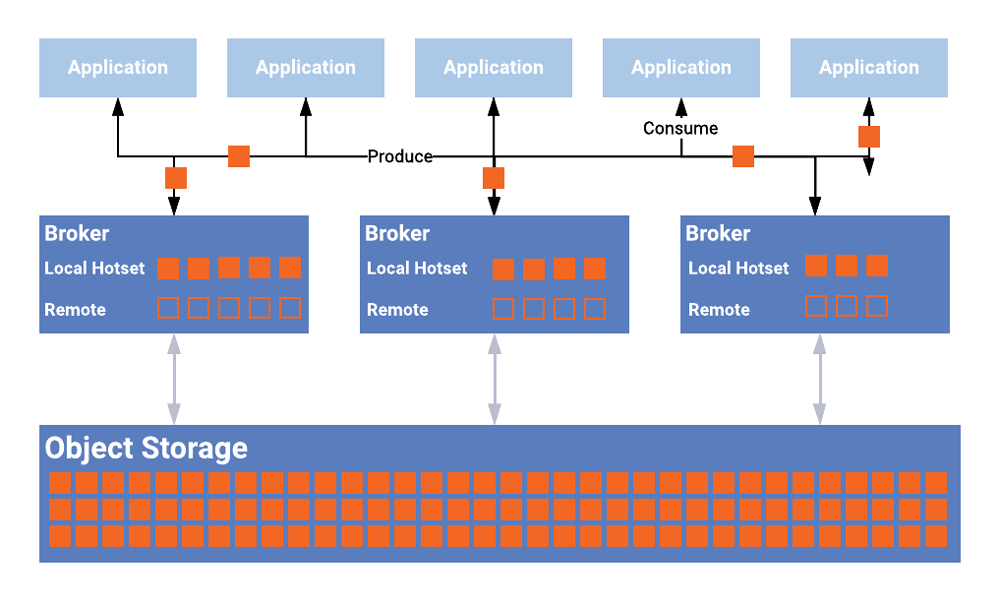
Tiered Storage allows the storage of data in Kafka long-term without having to worry about high cost, poor scalability, and complex operations. You can choose the local and remote retention time per Kafka topic. Another benefit of this separation is that you can now choose a faster SSD instead of HDD for local storage because it only stores the “hot data,” which can be just a few minutes or hours worth of information.
In the Confluent Platform 5.4-preview release, Tiered Storage supports the S3 interface. However, it is implemented in a portable way that allows for added support of other object stores like Google Cloud Storage and filestores like HDFS without requiring changes to the core of your implementation. For more details about the motivation behind and implementation of Tiered Storage, check out the blog post by our engineers.
Let’s now take a look at how Tiered Storage in Kafka can help simplify your machine learning infrastructure.
Data ingestion, rapid prototyping, and data preprocessing
Long-term storage in Kafka allows data scientists to work with historical datasets. One can either consume all data from the beginning or choose to do so just for a specific time span (e.g., all data from a specific week or month).
This enables rapid prototyping and data preprocessing. Beloved data science tools like Python and Jupyter can be used out of the box in conjunction with Kafka. Data consumption can also be done very easily, either via Confluent’s Python Client for Apache Kafka or via ksqlDB, which allows you to access and process data in Kafka with SQL commands.
ksqlDB even facilitates data integration with external systems like databases or object stores by leveraging Kafka Connect under the hood. This way, you can perform integration and preprocessing of continuous event streams with one solution:

Model training and model management both with or without a data lake
The next step after data preprocessing is model training. Either ingest the processed event streams into a data lake or directly train the model with streaming machine learning as discussed above using TensorFlow I/O and its Kafka plugin. There is no best option. The right decision depends on the requirements. Where the model is stored depends mainly on how you plan to deploy your model to perform predictions on new incoming events.
Since Tiered Storage provides a cheap and simple way to store data in Kafka long-term, there is no need to store it in another database for model training unless needed for other reasons. The trained model is also a binary. Typically, you don’t have just one model but different versions. In some scenarios, even various kinds of models are trained with different algorithms and are compared to each other. I have seen many projects where a key-value object store is used to manage and store models. This can be a cloud offering like Google Cloud Storage or a dedicated model server like TensorFlow Serving.
If you leverage Tiered Storage, you might consider storing the models directly in a dedicated Kafka topic like your other data. The models are immutable and can coexist in different versions. Or, you can choose a compacted topic to use only the most recent version of a model. This also simplifies the architecture as Kafka is used for yet another part of the infrastructure instead of relying on another tool or service.
Model deployment for real-time predictions
There are various ways to deploy your models into production applications for real-time predictions. In summary, models are either deployed to a dedicated model server or are embedded directly into the event streaming application:
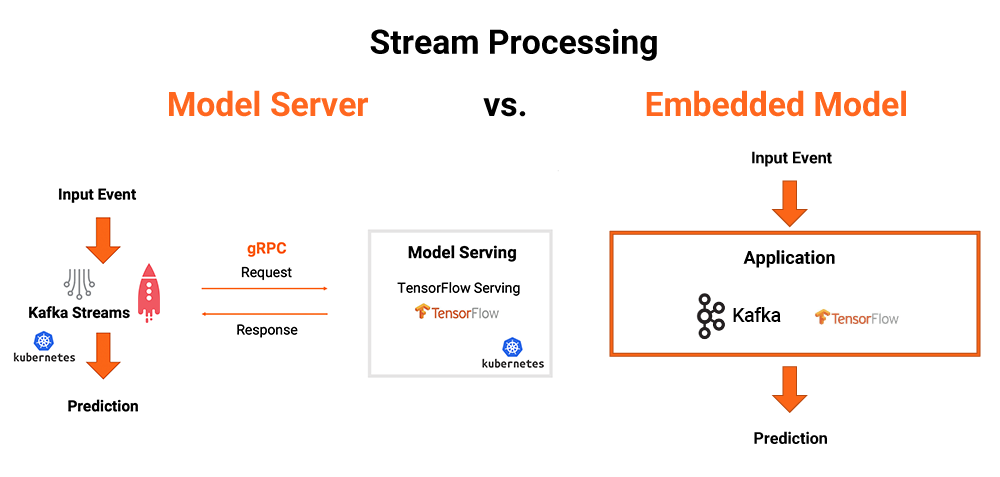
Both approaches have their pros and cons. The blog post Machine Learning and Real-Time Analytics in Apache Kafka Applications and the Kafka Summit presentation Event-Driven Model Serving: Stream Processing vs. RPC with Kafka and TensorFlow discuss this in detail.
There are more and more applications where the analytic model is directly embedded into the event streaming application, making it robust, decoupled, and optimized for performance and latency.
The model can be loaded into the application when starting it up (e.g., using the TensorFlow Java API). Model management (including versioning) depends on your build pipeline and DevOps strategy. For example, new models can be embedded into a new Kubernetes pod which simply replaces the old pod. Another commonly used option is to send newly trained models (or just the updated weights or hyperparameters) as a Kafka message to a Kafka topic. The client application consumes the new model and updates its internal usage at runtime dynamically.
The model predictions are stored in another Kafka topic with Tiered Storage turned on if the topic needs to be stored for longer. From here, any application can consume it. This includes monitoring and analytics tools.
Reusing the data ingestion and preprocessing pipeline
Always remember that data ingestion and preprocessing are required for model training and model inference. I have seen many projects where people built two separate pipelines with different technologies: a batch pipeline for model training and a real-time pipeline for model predictions.
In the blog post Questioning the Lambda Architecture, Confluent CEO Jay Kreps recommends the Kappa Architecture over splitting your architecture into a batch and real-time layer, which results in undue complexity. The Kappa Architecture uses event streaming for processing both live and historical data because an event streaming engine is equally suited for both types of use cases. Fortunately, I have some great news: what we have discussed above in this blog post is actually a Kappa Architecture. We can reuse the data ingestion and preprocessing pipeline that we built for model training. The same pipeline can also be used for real-time predictions instead of building a new pipeline.
Let’s take a look at the use case of the connected car GitHub project one more time:Do you see it? This is a Kappa Architecture where we use one event streaming pipeline for different scenarios like model training and real-time predictions.
As an important side note: Kappa does not mean that everything has to be real time. You can always add more consumers, including:
- Real-time consumers like a Kafka Streams business application for track and trace and logistics, or a time series database like InfluxDB or Prometheus for real-time analytics of possible traffic jams
- Near-real-time consumers like an Elasticsearch cluster to index new events into its text search
- Batch consumers like a Hadoop cluster for doing complex MapReduce calculations to create hourly or daily reports about traffic data
- REST consumers that provide a request-response interface to allow queries from mobile apps
Real-time monitoring and analytics
We discussed how to leverage streaming machine learning and Tiered Storage to build a scalable real-time infrastructure. However, model training and model deployment are just two parts of the overall machine learning tasks. In the beginning, teams often forget about another core piece of a successful machine learning architecture: monitoring!
Monitoring, testing, and analysis of the whole machine learning infrastructure are critical but hard to realize in many architectures. It is much harder to do than for a traditional system. The ML Test Score by Google explains these challenges in detail:
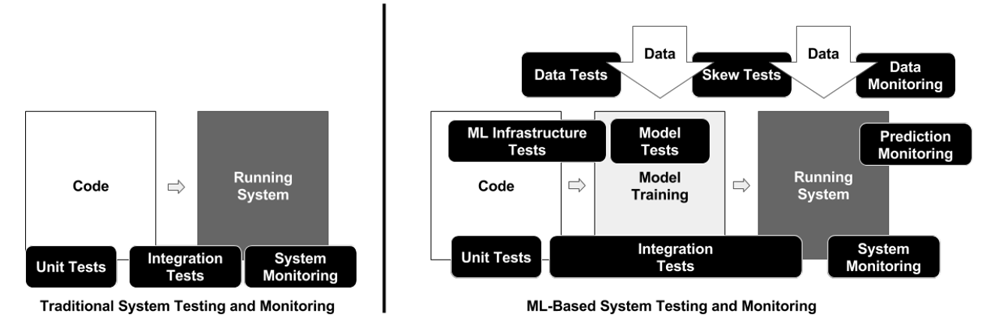
With our streaming machine learning architecture, including long-term storage, we can solve these challenges. We can consume everything in real time and/or using Tiered Storage:
- Data used for model training
- Preprocessed data and model features
- Data used for model predictions
- Predictions
- Errors (wrong data types, empty messages, etc.)
- Infrastructure monitoring (like JMX data of the Kafka brokers and Kafka clients)
The speed of data processing depends on the scenario—whether we want new events in real time, historically, or within a specific historical timespan, such as from the last hour or month. All this information is stored in different Kafka topics. In addition, tools like ksqlDB or any external monitoring tool like Elasticsearch, Datadog, or Splunk can be used to perform further analysis, aggregations, correlations, monitoring, and alerting on the event streams. Depending on the use case, this happens in real time, occurs in batch, or leverages design patterns like event sourcing for reprocessing data in the occurred order.
Streaming machine learning and Tiered Storage simplify machine learning infrastructure
An event streaming platform with Tiered Storage is the core foundation of a cutting-edge machine learning infrastructure. Streaming machine learning—where the machine learning tools directly consume the data from the immutable log—simplifies your overall architecture significantly. This means:
- You don’t need another data lake
- You can leverage one pipeline for model training and predictions
- You can provide a complete real-time monitoring infrastructure
- You can enable access through traditional BI and analytics tools
The described streaming architecture is built on top of the event streaming platform Apache Kafka. The heart of its architecture leverages the event-based Kappa design. This enables patterns like event sourcing and CQRS, as well as real-time processing and the usage of communication paradigms and processing patterns like near real time, batch, or request-response. Tiered Storage enables long-term storage with low cost and the ability to more easily operate large Kafka clusters.
This streaming machine learning infrastructure establishes a reliable, scalable, and future-ready infrastructure using frontline technologies, while still providing connectivity to any legacy technology or communication paradigm.
Get started with Tiered Storage and machine learning
If you’re ready to take the next step, you can download the Confluent Platform to get started with Tiered Storage in preview and a complete event streaming platform built by the original creators of Apache Kafka.
Avez-vous aimé cet article de blog ? Partagez-le !
Abonnez-vous au blog Confluent



Empowering Customers: The Role of Confluent’s Trust Center
Learn how the Confluent Trust Center helps security and compliance teams accelerate due diligence, simplify audits, and gain confidence through transparency.



Unified Stream Manager: Manage and Monitor Apache Kafka® Across Environments
Unified Stream Manager is now GA! Bridge the gap between Confluent Platform and Confluent Cloud with a single pane of glass for hybrid data governance, end-to-end lineage, and observability.