[Virtual Event] Agentic AI Streamposium: Learn to Build Real-Time AI Agents & Apps | Register
Real-Time Gaming Infrastructure for Millions of Users with Apache Kafka, ksqlDB, and WebSockets
The global video game market is bigger than the music and film industry combined. It includes Triple-A, casual/mid-core, mobile, and multiplayer online games. Various business models exist, such as hardware sales, game sales, free-to-play + in-game purchases, one-time in-game purchases (skins, champions, misc.), gambling (loot boxes), game-as-a-service, game-infrastructure-as-a-service, merchandise, live betting, casino games, and so on.
With the evolution of the gaming industry, the demand for real-time data integration and processing at scale increased significantly. Many gaming enterprises leverage an event streaming platform powered by Apache Kafka® and its broad ecosystem like Kafka Connect, Schema Registry, and ksqlDB to process data in motion for various use cases such as providing a better customer experience, increasing the gaming revenue, and reducing the risk of fraudulent gaming behavior or payments. A few examples include:
- Disney+ Hotstar: Gaming service for millions of cricket fans in India
- Big Fish Games: Real-time analytics of game telemetry data for live operations
- Sony PlayStation: Competitive pricing analysis of game titles across online video game marketplaces
- Unity: Real-time monetization network
- William Hill: A trading platform for millions of bets every day
You can learn more details in this on-demand webinar: Kafka and Big Data Streaming Use Cases in the Gaming Industry.
This blog post shows a real-time gamification demo to integrate gamers via WebSockets to the data streaming backend infrastructure.
Real-time streaming for millions of players with a serverless infrastructure
Today, there are two common IT trends related to the gaming idustry: implementing a serverless infrastructure to focus on business problems, and addressing the challenges associated with the integration of the players.
Fully managed event streaming is the answer. Gaming companies want and need to focus on business value, not operating the event streaming infrastructure. Confluent Cloud is the logical choice for many gaming deployments because it includes messaging and data ingestion, as well as data integration with fully managed connectors, data processing with ksqlDB, and security and data governance on top of the whole event-based architecture.
The last-mile integration with millions of mobile devices, computers, and game consoles is challenging. Kafka was never built for this. WebSockets is a complementary technology to implement the integration of players in real time at scale.
The following details a concrete example of how to implement the last-mile integration at scale in real time, and is similar to the Disney+ Hotstar example above. The demo shows how Kafka and WebSockets are the perfect combined solution for end-to-end data integration and correlation in real time.
Extending Kafka messaging across the web to millions of devices with WebSockets
Traditionally, the HTTP protocol has been used to achieve web messaging. Techniques like HTTP (long) polling have been used to get fresh messages from the server side, the polling frequency determining the latency of the messages. So, to reduce the latency of messages and achieve a decent real-time experience for users, the polling frequency needed to be increased. But polling often means reconnecting frequently to the server which results in immense pressure on the web server when dealing with lots of clients. In addition, if the client runs from the web browser, at each HTTP request sent to the server, the web browser appends by default hundreds of bytes as HTTP headers, putting additional pressure on the web server and increasing the bandwidth costs.
Unlike HTTP, the WebSocket protocol keeps a single, persistent connection with the server so that any new message is sent to the client (or vice versa) as soon as it is available, reducing the pressure on the server and resolving the latency and bandwidth problems. That said, while the WebSocket protocol creates the conditions for web messaging scalability, the scalability of a WebSockets server depends on the quality of its implementation.
Therefore, the WebSocket protocol is a good candidate for extending Kafka’s real-time event streaming over the internet. Kafka, however, does not support the WebSocket protocol, and simply adding support for the WebSocket protocol in Kafka would not scale. Kafka is designed for connecting backend systems. Moreover, a Kafka client connects simultaneously to multiple Kafka servers which is not practical for a web client.
Since it is not optimized to handle lots of connections, Kafka should offload the web messaging task to another messaging layer which would preserve its key advantages such as guaranteed delivery, message ordering, scalability to handle large volumes of messages, and high availability.
Several enterprise messaging solutions exist for extending Kafka over WebSockets across the internet. Because the WebSocket protocol is a low-level transport protocol that uses data frames rather than messages, all these enterprise messaging solutions expose a higher level messaging protocol at the application layer on top of the low-level framing protocol of WebSockets. Some of these solutions employ the MQTT protocol, a lightweight application-layer publish/subscribe messaging protocol which works over WebSockets.
MigratoryData is one of these enterprise messaging solutions. However, it does not employ the MQTT protocol. The MQTT protocol is a standard for the IoT industry. It is designed to be simple enough to accommodate the constrained IoT devices. For example, it implements guaranteed delivery using simple acknowledgements which can lead to scalability issues such as feedback implosions for non-IoT use cases, such as real-time web and mobile apps with lots of users. Instead, MigratoryData chose to employ its application layer protocol, which is optimized to handle up to 10 million concurrent WebSocket clients on a single commodity machine. It is a proven protocol used for over a decade in large-scale mission-critical deployments with millions of users. Also, it is designed to achieve guaranteed delivery, message ordering, scalability, and high availability. To learn more, check out the paper Reliable Messaging to Millions of Users with MigratoryData.
MigratoryData provides two integrations with Kafka. One is based on Kafka connectors, specifically, source and sink connectors using the Kafka Connect service. The other one is based on a Kafka add-on which integrates natively with Kafka, without using an intermediary service.
This post shows how to create an interactive gamification feature that scales and demonstrates how feasible and cost-effective it is to build such interactive features using MigratoryData with the Kafka-native add-on enabled, Kafka, and WebSockets to engage in real time with millions of users.
Real-time gamification demo with Kafka and WebSockets
During the last edition of the World Cricket Cup, the OTT platform Disney+ Hotstar counted 25.3 million simultaneous viewers, a world record in terms of audience. The OTT platform uses gamification to engage with the large number of cricket fans in India, leveraging the Watch ’N Play interactive game, where viewers of a live cricket match can answer questions in real time about what happens on the next ball to win points and redeem prizes. Check out this presentation to learn how Hotstar leverages the Confluent ecosystem to realize the event streaming backend infrastructure at scale.
Inspired by the Hotstar gamification use case that requires bidirectional real-time messaging and event streaming between the backend infrastructure and millions of users, we built an interactive gamification demo. The demo consists of asking a live question every 20 seconds with a 10-second response deadline. Therefore, a player of the demo has 10 seconds to answer a live question to win points. The demo also displays a leaderboard with the 10 highest scoring players.
The demo consists of the following components alongside MigratoryData and Kafka:
| Component Name | Description |
| UI | A real-time web application (MigratoryData subscriber and publisher) |
| Questions Generator | Generates live questions (Kafka producer) |
| Answers Processor | Processes the answer received from a player (Kafka consumer) and publishes the new points won by that player (Kafka producer) |
| Leaderboard Processor | Updates the leaderboard with the new points won by a player (Kafka consumer), gets a leaderboard request (Kafka consumer), and publises the current leaderboard following a request (Kafka producer) |
The UI of the demo consists of two views: a Play view and a Leaderboard view.
Play view
The following MigratoryData subjects, Kafka topics, and keys are used to model the real-time interactions of the Play view:
| Kafka (Topic, Key) | MigratoryData Subject | Description |
| (question, null) | /question | Used by the Questions Generator to generate live questions |
| (answer, x) | /answer/x | Used by the player with the id x to deliver the answer to a live question |
| (result, x) | /result/x | Used by the Answers Processor to let the player with the id x, as well as the Leaderboard Processor, know how many points the player won after having answered a live question |
The mapping between MigratoryData subjects and Kafka topics and keys is automatic by simply adding the Kafka topics consumed by MigratoryData, e.g., question and result, to the configuration file addons/kafka/consumer.properties of MigratoryData as follows:
topics = question,result |
To learn more about the dynamic mapping between the MigratoryData subjects to the Kafka topics and keys, you can read Connecting Millions of End-User Devices to Your Kafka Pipelines Over WebSockets or the MigratoryData documentation. You can also read more about the concepts of MigratoryData and Kafka and their correspondence in this blog post.
The real-time information flow between the components of the demo using these subjects, topics, and keys is depicted in the following diagram:
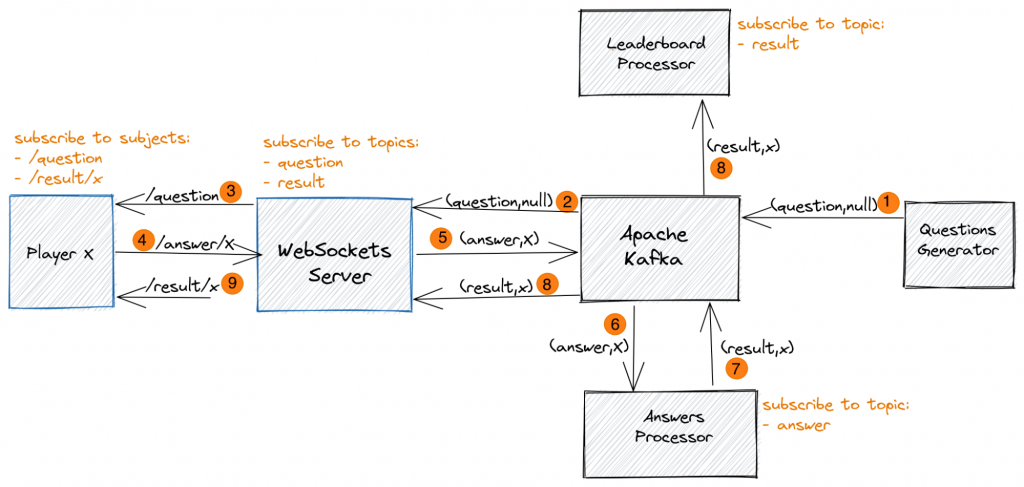
A Player x that opens the Play view connects to MigratoryData WebSockets Server using a persistent WebSocket connection and subscribes to the subjects /question and /result/x. As explained above, MigratoryData WebSockets Server is configured to subscribe to the Kafka topics question and result, Leaderboard Processor subscribes to the Kafka topic result, and Answers Processor subscribes to the Kafka topic answer. The workflow of messages is as follows:
- Questions Generator generates a live question every 20 seconds by publishing a message on the topic question ❶
- MigratoryData WebSockets Server is subscribed to the Kafka topic question, so it gets the live question ❷ and streams it to all players subscribed to the subject /question, according to the automatic mapping between Kafka topics and MigratoryData subjects
- Player x is subscribed to the subject /question, so it gets the live question ❸
- Player x has up to 10 seconds to answer the live question by publishing to MigratoryData WebSockets Server an answer message on the subject /answer/x ❹
- MigratoryData WebSockets Server gets the answer message on the subject /answer/x and publishes it to Kafka on the topic answer with the key x, according to the automatic mapping between topics and subjects ❺
- Answers Processor is subscribed to the topic answer, so it consumes the answer message ❻, checks if the answer provided by Player x is correct, and sends back to Kafka the points won by the Player by publishing a result message on the topic result with the key x ❼
- The result message is consumed by the Leaderboard Processor as it is subscribed to the topic result and updates its list of top players ❽. This message is also consumed by MigratoryData WebSockets Server as it is subscribed to the Kafka topic result ❽
- MigratoryData WebSockets Server delivers the result message to any player subscribed to the subject /result/x, according to the automatic mapping between topics and subjects
- Finally, because Player x is subscribed to the subject /result/x, it gets the result message with the points it won ❾
Leaderboard view
The following MigratoryData subjects, Kafka topics, and keys are used to model the real-time interactions of the Leaderboard view:
| Kafka (Topic, Key) | MigratoryData Subject | Description |
| (gettop, null) | /gettop | Used by any player to request the leaderboard (the id x of the player is included in the content of the message) |
| (top, x) | /top/x | Used by Leaderboard Processor to let the player with the id x, which requested the leaderboard, know the current list of the top 10 players |
The mapping between MigratoryData subjects and Kafka topics and keys is automatic by simply adding to the list of the Kafka topics consumed by MigratoryData the topic top. Therefore, the parameter topics of the configuration file addons/kafka/consumer.properties of MigratoryData should be as follows:
topics = question,result,top
The real-time information flow between the components of the demo using these subjects, topics, and keys is depicted in the following diagram:
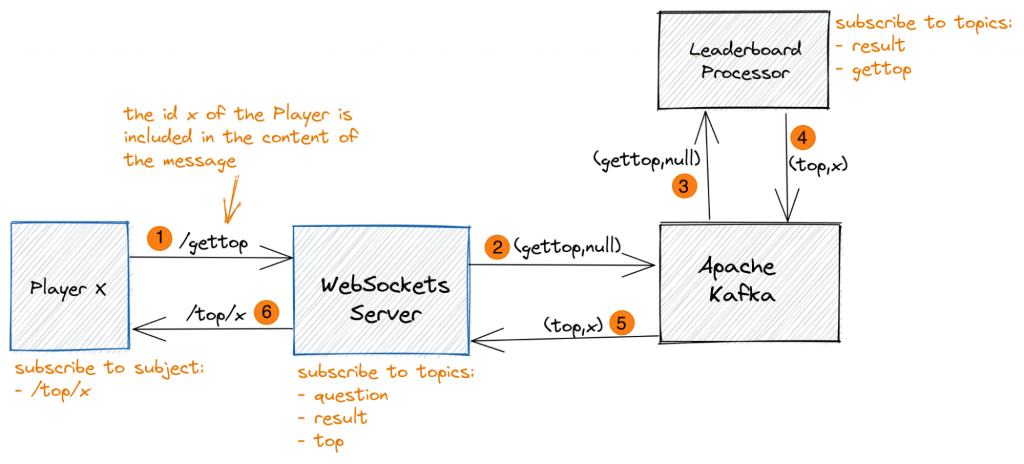
A Player x that opens the Leaderboard view connects to MigratoryData WebSockets Server using a persistent WebSocket connection and subscribes to the subject /top/x. As explained above, MigratoryData WebSockets Server is configured to subscribe to the Kafka topics question, result, and top, and Leaderboard Processor subscribes to the Kafka topics result and gettop. The workflow of messages is as follows:
- Player x publishes a request message to MigratoryData WebSockets Server containing its id x on the subject /gettop to get the updated list of the top 10 players ❶
- MigratoryData WebSockets Server gets the request message on the subject /gettop and sends it to Kafka on the topic gettop with a null key ❷, according to the automatic mapping between topics and subjects
- Leaderboard Processor gets the request message as it is subscribed to the topic gettop ❸
- Once the request is received, the Leaderboard Processor sends back to Kafka a response message with the current leaderboard on the topic top with the key x ❹
- MigratoryData is subscribed to the topic top, so it gets the response message ❺, and pushes it to any player subscribed to the subject /top/x, according to the automatic mapping between topics and subjects
- Player x is subscribed to the subject /top/x, so it gets the response message with the updated list of the top 10 players ❻
Implementation
The source code of the demo is available on GitHub. The folder frontend contains the source code of the UI. The folder backend contains the source code of the Leaderboard Processor, Answers Processor, and Questions Generator.
Simplifying the business logic: Implementation using ksqlDB
We rearchitected the initial implementation of the Play view of the demo application using ksqlDB to simplify the solution leveraging Kafka-native stream processing. With a few ksqlDB queries we can eliminate the backend components Answers Processor, Questions Generator, and Leaderboard Processor of the demo application. For example, a simple insert into a ksqlDB stream replaces the functionality of the Questions Generator component:
INSERT INTO INPUT_QUESTION (id, question, answers, points) VALUES ('q5',
'What is the number of strokes to win?', ARRAY['less than 10', 'between 10
and 20', 'between 20 and 30', 'more than 30'], 100)
The backend implementation based on ksqlDB is available on GitHub. The event streaming infrastructure can be deployed by Docker Compose using the Docker images provided by MigratoryData for the WebSockets Server and by Confluent for Kafka and ksqlDB.
The deployment of the backend can be further simplified by using Confluent Cloud. This way, the focus can be on the business side since the entire event streaming infrastructure is provided as a truly serverless offering, including Kafka, connectors, ksqlDB, data governance, security, and more. If you want to learn more about the difference between a truly serverless and complete Kafka offering (i.e., self-driving car) compared to a self-managed Kafka deployment (i.e., car engine), check out this blog post.
Vertical scalability of the WebSocket-Kafka integration
We performed a benchmark test that demonstrates that a single instance of MigratoryData running on a commodity server with 2 x Intel Xeon E5-2670 CPU and 64 GB RAM can handle one million concurrent players. We used a benchmark scenario covering the Play view, which represents the main activity of the demo (the Leaderboad View typically involves a small number of concurrent players, so it was excluded by our benchmark). The following Grafana dashboard produced by the MigratoryData’s monitoring during the benchmarking period shows that each question triggered by the backend is multiplexed by MigratoryData into one million messages to the one million players. In addition, MigratoryData can receive one million answer messages from the one million players, and send back one million result messages to the one million players for each question.
Linear horizontal scalability of the WebSocket-Kafka integration
MigratoryData can be clustered to scale horizontally. Moreover, MigratoryData with the Kafka-native add-on enabled does not share any user state across the cluster. Each instance of MigratoryData running in the cluster is independent of the other instances. Therefore, MigratoryData with the Kafka-native add-on enabled scales linearly. To exemplify the linear scalability, we show that by adding a new instance of MigratoryData to the cluster, running on a machine with the same hardware, the cluster capacity increases to two million concurrent users as shown by the following Grafana dashboard.
Kafka and WebSockets enables real-time gaming at any scale
The gaming industry needs to process high volumes of data in real time to provide a great customer experience and make good revenue margins. This blog post shows how Kafka and WebSockets are a great combination to build end-to-end data integration, processing, and analytics in real time at scale for millions of users.
Confluent Cloud provides a serverless ecosystem for event streaming including fully managed connectors, data processing, data governance, and security. In combination with MigratoryData, the last-mile integration to millions of users is possible in real time.
Avez-vous aimé cet article de blog ? Partagez-le !
Abonnez-vous au blog Confluent



From Dumb Pipes to a Smart Data Plane: Introducing Schema IDs in Apache Kafka® Headers
Confluent’s Schema IDs in headers transform Kafka from "dumb pipes" to a "smart data plane." By moving metadata out of payloads, teams can schematize topics without breaking legacy apps or requiring big-bang migrations. This unlocks governed, AI-ready data for Flink and lakehouses with ease.


Queues for Apache Kafka® Is Here: Your Guide to Getting Started in Confluent
Confluent announces the General Availability of Queues for Kafka on Confluent Cloud and Confluent Platform with Apache Kafka 4.2. This production-ready feature brings native queue semantics to Kafka through KIP-932, enabling organizations to consolidate streaming and queuing infrastructure while...