[Virtual Event] Agentic AI Streamposium: Learn to Build Real-Time AI Agents & Apps | Register
Track Transportation Assets in Real Time with Apache Kafka and Kafka Streams
Apache Kafka® is a distributed commit log, commonly used as a multi-tenant data hub to connect diverse source systems and sink systems. Source systems can be systems or records, operational databases, or any producer application, like an MQTT application. Kafka is heavily used to transform ETL jobs from batch mode to near-real-time mode. Apache Kafka is increasingly becoming the de facto multi-tenant, distributed event streaming platform for all types of enterprises across all verticals, democratizing data for both internal and external users or applications of the data.
What problem are we solving today?
Tracking transportation assets is one of many industries where Kafka is making a huge difference. We will examine how Kafka, Kafka Streams, Elasticsearch, and a visualization tool such as Kibana can be used to track the movement of assets in real time, specifically for trams, buses, and high-speed electric trains used in the Helsinki Region Transport (HSL) system. Transportation assets act as edge IoT devices that publish their status, including position per second.
A producer application subscribes to an MQTT server, which produces geolocation information about the trams running in the Helsinki area. Data from the MQTT server is written into the Kafka topic. Data is enriched into a format that puts the geolocation data into a nested JSON structure, which makes it easy for Elasticsearch to consume and display on a dashboard in Kibana. This entire workflow can be accomplished with minimal effort on the development side.
Zooming out to see the big picture
![]()
Let’s dig deeper into each of the components involved, starting with the Java client that produces the data stream from the MQTT server.
The MQTT source produces data into the server. The Java client subscribes to it and writes data into a Kafka topic called vehicle-positions. The producer will expect the topic vehicle-positions to already be created, or it will create it for you; however, auto.topic.create should be set to true. The relevant data comes from the HSL, where vehicles publish their data to the MQTT server every second. Each MQTT message has two parts: the topic and the binary payload. For ease of use, the Java client is Dockerized in this example. Here is a sample command to use if the authentication mechanism is PLAIN:
docker container run --network=host --rm -e KAFKA_BROKERS= -e KAFKA_USERNAME= -e KAFKA_PASSWORD= -it proton69/java-producer:paramsV2
The sample command looks like the following:
docker container run --network=host --rm -e KAFKA_BROKERS=ip-10-9-8-13.us-west-2.compute.internal:9092 -e KAFKA_USERNAME=test -e KAFKA_PASSWORD=test123 -it proton69/java-producer:paramsV2
Once the data is in the Kafka topic, you can easily filter the data based on vehicle types. For example, one topic could filter data for buses, ferries, or just trams. A unit of scaling in Kafka is called a partition. If the current number of partitions is unable to handle the throughput, then you can alter the Kafka topic to increase the number of partitions, but keep in mind that consumers rely on data partitioned by a key. If you want to enhance the producer app, the source code can be found on GitHub.
The stream of per-second vehicle position data is written into the Kafka topic vehicle-positions. However, in order for this data to be consumed by a map widget into Kibana, messages need to be massaged and prepared beforehand. This is where Kafka Streams comes in very handy. Kafka Streams makes it easy to perform data enrichment that is simple, scalable, and if needed, exactly-once. For a more streamlined approach, you can use ksqlDB, which allows you to process events using SQL like language, consume data from a topic, enrich the data, and send it to downstream systems.
The simplest way to use the Kafka Streams app is shown below:
java -jar
You can run this on a broker, as it needs access to the vehicle-positions topic:
java -jar vehicle-position-reformat-1.0-SNAPSHOT-jar-with-dependencies.jar
The Streams app helps us do this, JSON message in vehicle-positions looks like below:
... "route": "1009", "occu": 0, "lat": 60.177906, "long": 24.949954 }
Using Kafka Streams we can enrich it, fairly easily. After enrichment, the data is written into the topic vehicle-positions-enriched, the JSON message looks like the following:
...
"route": "1009",
"occu": 0,
"location": {
"lat": 60.177906,
"long": 24.949954
}
Data is now in the format that we need, so let’s push the data into Elasticsearch using a sink connector. Setting up the sink connector for Elasticsearch is fairly straightforward. Prior to setting up the connector, a dynamic template needs to be set up on the Kibana side to recognize the geolocation data. The template below captures the data coming from the Kafka topic and maps the location.lat and location.long to geo_point in Kibana, which can be used to plot a real-time map dashboard.
{
"_doc": {
"dynamic_templates": [
{
"dates": {
"mapping": {
"format": "epoch_millis",
"type": "date"
},
"match": "ts"
}
},
{
"locations": {
"mapping": {
"type": "geo_point"
},
"match": "*location"
}
}
]
}
}
This is the configuration that was used in the setup:
curl -X PUT -H "Content-Type: application/json" --data '
{
"connector.class": "io.confluent.connect.elasticsearch.ElasticsearchSinkConnector",
"type.name": "_doc",
"topics": "vehicle-positions-enriched",
"consumer.override.auto.offset.reset": "latest",
"key.ignore": "true",
"schema.ignore": "true",
"name": "vehicle-positions-elastic",
"value.converter.schemas.enable": "false",
"connection.url": "http://ip-10-9-8-39.us-west-2.compute.internal:9200",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"key.converter": "org.apache.kafka.connect.storage.StringConverter"
}' http://ip-10-9-8-13.us-west-2.compute.internal:8083/connectors/vehicle-positions-elastic/config
The connector status is shown below:
curl -X GET http://localhost:8083/connectors/vehicle-positions-elastic/status
It’s always good practice to add a dynamic template for the Elasticsearch index:
{
"_doc": {
"dynamic_templates": [
{
"dates": {
"mapping": {
"format": "epoch_millis",
"type": "date"
},
"match": "ts"
}
},
{
"locations": {
"mapping": {
"type": "geo_point"
},
"match": "*location"
}
}
]
}
}
Code for the above Streams application can be found on GitHub.
Data should start flowing from the Kafka topic to the Elasticsearch index. To visualize the data, we will use Kibana.
Go to Kibana > Management > Index Management, where you should see the vehicle-positions-enriched index.
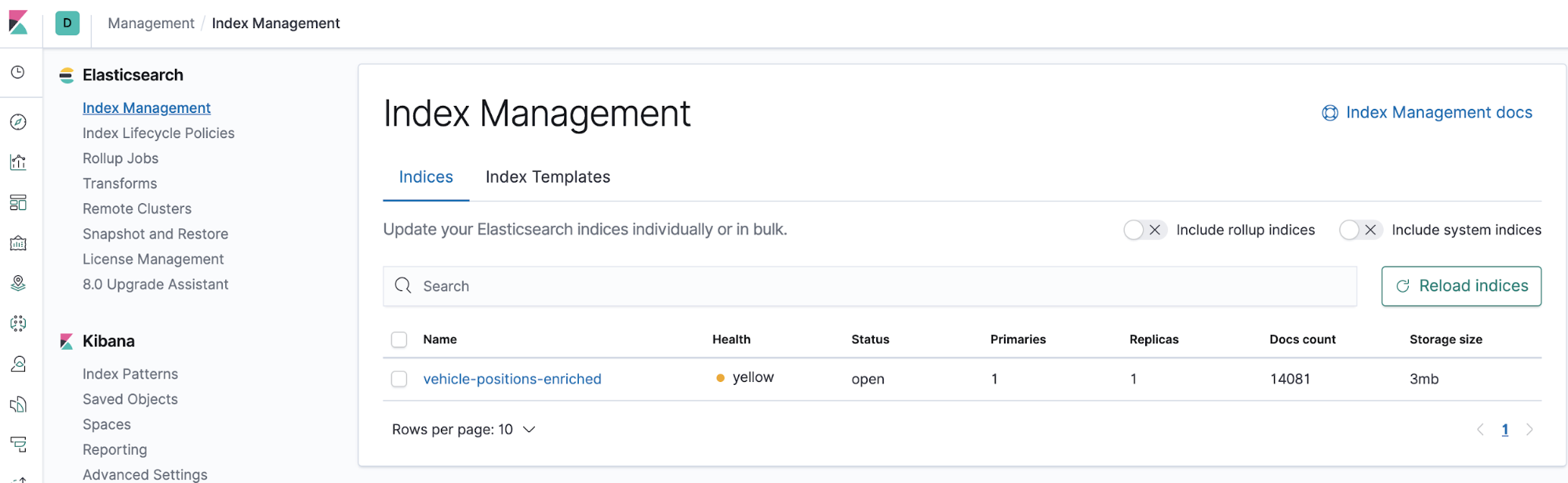
Shortly after, the docs will start populating in the index, which can be seen in the “Docs count” column.
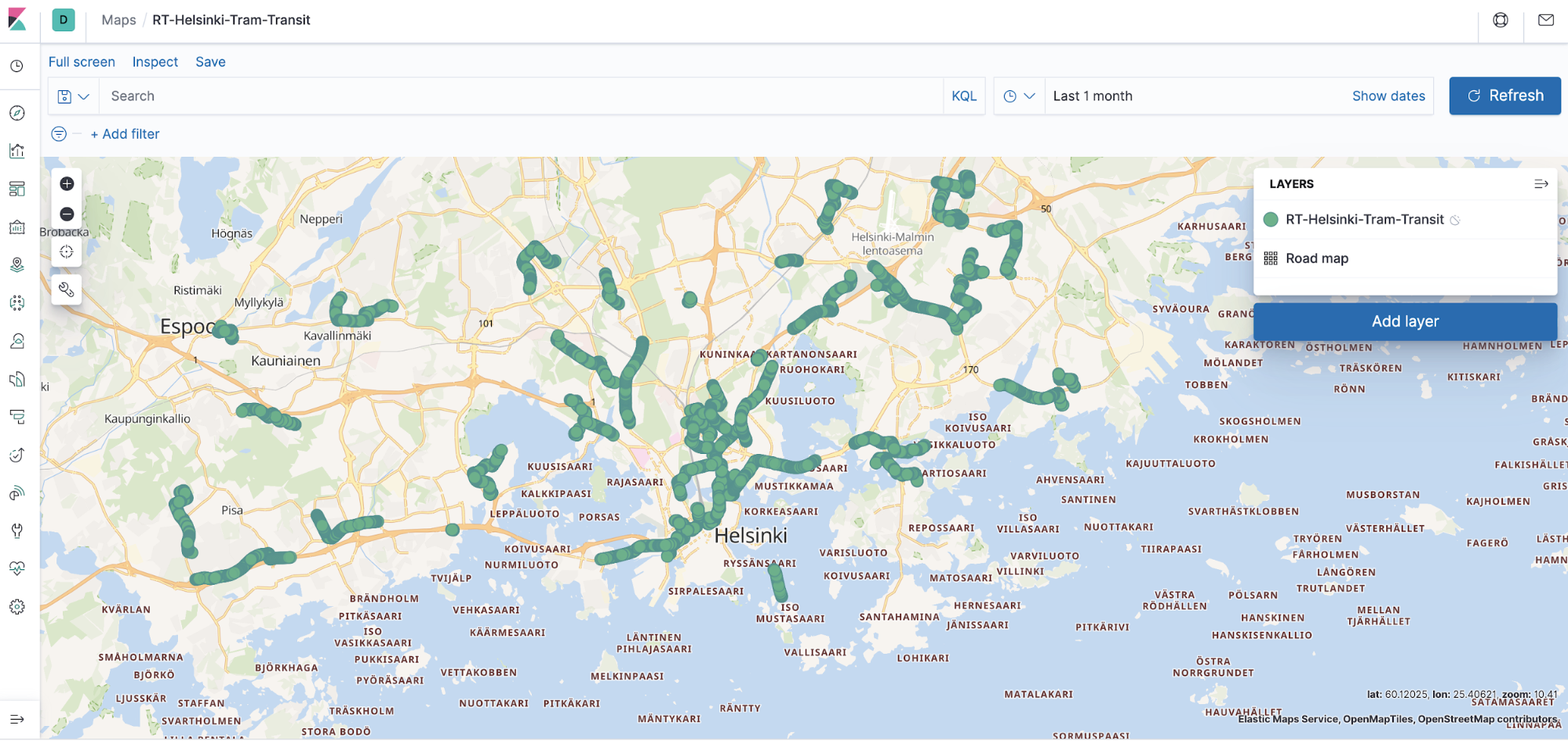
Kibana has a maps widget that is easy to use, and we can see the geolocation data by plotting a graph, which can later be used in the dashboard app of Kibana.
From the Kibana homepage, click App Maps > Create Map > Add Layer > {Select Data Source} > Documents > Index Pattern > Add Layer.
Name the “Layer Settings,” and in the “Sorting” section, select “Speed” (abbreviated as “spd”). Click Save and Close.
You should now have a real-time dashboard running on Kibana.
Conclusion
The entire data pipeline we’ve just built is real time. The producer produces data into a Kafka topic; the stream processing query runs continuously, processes the incoming JSON data, and enriches it in real time; then through the Kafka Connect framework, the Elasticsearch connector sinks the data into Elasticsearch, again in real time, and eventually makes its way to the Kibana map application for a real-time dashboard. As a dynamic platform, Kafka makes processing data in real time possible so that companies can be less reactive and more proactive about meeting the demands of tomorrow starting today.
To start building applications with Kafka Streams, download the Confluent Platform and get started with the leading distribution of Apache Kafka.
Avez-vous aimé cet article de blog ? Partagez-le !
Abonnez-vous au blog Confluent



How to Implement Your First ML Function in Streaming
Learn how to add your first ML model to a real-time streaming pipeline. Learn a simple, low-risk pattern for inference, scoring, and deployment with Apache Kafka®.



Sustainable Streaming Architectures: A GreenOps Guide to Efficient, Low-Carbon Data Systems
Design energy-efficient, low-cost streaming systems. Learn GreenOps patterns to reduce compute waste, optimize storage, and lower the carbon footprint of real-time data.