[Virtual Event] Agentic AI Streamposium: Learn to Build Real-Time AI Agents & Apps | Register
Announcing ksqlDB 0.23.1
We’re pleased to announce ksqlDB 0.23.1! This release allows you to now perform pull queries on streams, which makes it much easier to find a given record in a topic. You can also now access topic partition and offset through new pseudocolumns, and use grace periods when joining streams. All of these features are now available in Confluent Cloud. We’re excited to share them with you, and we will cover the most notable changes in this blog post. Check out the changelog for a complete list of features and fixes.
Pull queries on STREAMs
ksqlDB 0.23.1 now includes the ability to run pull queries over streams! This feature gives you the ability to easily scan and filter over your topics using SQL. This is a great way to do useful things like:
- Inspect the data in your streams
- Retrieve specific records from your streams
- Debug your data pipelines
Previously, a query like SELECT * FROM MY_STREAM; would return an error directing you to add EMIT CHANGES on the end, which results in a push query. However, that push query would only subscribe you to future records. You could additionally tell ksqlDB to give you the past records by first setting SET 'auto.offset.reset' = 'earliest';. That would get you a scan over the whole stream (good), but because it was a push query, you’d have to cancel the query once it got to the end (bad: how are you supposed to know when you’re at the end?). Simple things should be easy, so we wanted to give you a simple way to just take a peek at the data in your streams.
Starting in ksqlDB 0.23.1, you can run a query such as SELECT * FROM MY_STREAM;, and it will:
- Print out the current contents of that stream, from the start to the end (determined when you issue the query)
- Terminate when it gets to the end (that is, you don’t have to cancel the query at the end)
As with other pull queries, you can filter and project. For example:
- SELECT Name, Position FROM MY_STREAM WHERE USER_ID = 12345;
- SELECT * FROM MY_STREAM WHERE UPDATED >= '2021-09-01' AND UPDATED < '2021-10-01';
A word of caution: each time you run these queries, ksqlDB will scan over the entire contents of the topic that backs your stream. Apache Kafka® is very good at serving sequential reads, but you should still be aware of the potential load you are putting on your data infrastructure in on-prem situations and also of the data transfer costs you are incurring in Confluent Cloud. From a broker load perspective, running a pull query on a STREAM is just as if you created a Kafka Consumer and scanned the entire topic.
Future improvements to this feature will include the ability to limit the underlying topic scan based on row timestamps included in the query, the ability to find out how much data is scanned during a query (and therefore estimate its cost), and the ability to aggregate the query result (for example, to count the number of records in the stream that match the query).
Accessing record partition and offset data
A Kafka message consists of a message key, value, optional headers, and associated metadata such as timestamp, topic partition, and topic offset. ksqlDB users are familiar with accessing key columns, value columns, and message timestamp (via ROWTIME). With ksqlDB 0.23.1, ksqlDB also provides access to topic partition and offset via two new pseudocolumns, ROWPARTITION and ROWOFFSET.
These new pseudocolumns can be especially helpful while developing a new query, to aid in your understanding of how input records are processed into output records. They may also be used to filter out particular messages or ranges of messages.
View partition and offset information for messages in your stream:
## example transactions stream
CREATE STREAM transactions (
id BIGINT,
day VARCHAR,
description VARCHAR
) WITH (
KAFKA_TOPIC = 'transactions',
VALUE_FORMAT = 'JSON',
PARTITIONS = 6
);
SELECT *, ROWPARTITION, ROWOFFSET FROM transactions EMIT CHANGES;
## sample output:
## +------------------------+------------------------+------------------------+------------------------+------------------------+
## |ID |DAY |DESCRIPTION |ROWPARTITION |ROWOFFSET |
## +------------------------+------------------------+------------------------+------------------------+------------------------+
## |100001 |2021-12-28 |Houseplant Depot |0 |0 |
## |100000 |2021-12-28 |Cafe Anna |4 |0 |
## |100002 |2021-12-31 |Home Furnishings Inc |4 |1 |
Propagate source partition and offset information as part of a persistent query:
CREATE TABLE EOD_MESSAGES WITH (FORMAT = 'JSON')
AS SELECT day,
ROWPARTITION as row_partition,
min(ROWOFFSET) as min_offset,
max(ROWOFFSET) as max_offset
FROM transactions
GROUP BY day, ROWPARTITION;
SELECT * FROM EOD_MESSAGES EMIT CHANGES;
## sample output:
## +------------------------------+------------------------------+------------------------------+------------------------------+
## |DAY |ROW_PARTITION |MIN_OFFSET |MAX_OFFSET |
## +------------------------------+------------------------------+------------------------------+------------------------------+
## |2021-12-28 |0 |0 |0 |
## |2021-12-28 |4 |0 |0 |
## |2021-12-31 |4 |1 |1 |
Filter messages based on partition and offset:
SELECT *, ROWPARTITION, ROWOFFSET FROM transactions WHERE NOT (ROWPARTITION = 4 AND ROWOFFSET = 0) EMIT CHANGES; ## sample output: ## +------------------------+------------------------+------------------------+------------------------+------------------------+ ## |ID |DAY |DESCRIPTION |ROWPARTITION |ROWOFFSET | ## +------------------------+------------------------+------------------------+------------------------+------------------------+ ## |100001 |2021-12-28 |Houseplant Depot |0 |0 | ## |100002 |2021-12-31 |Home Furnishings Inc |4 |1 |
Use of ROWPARTITION and ROWOFFSET is limited to streaming queries only, and may not be used in pull queries today.
GRACE PERIOD on stream-stream joins
In ksqlDB, when you join two streams, you must specify a WITHIN clause for matching records that occur within a specified time interval. In Kafka Streams, an additional grace period may be configured. Previous versions of ksqlDB used a fixed grace period of 24 hours.
The WITHIN time interval in a join specifies the join window size, while the grace period defines how long out-of-order records will be accepted. The ability to specify the grace period for stream-stream joins impacts the disk space utilization. This is because a window needs to stay on disk until the grace period has elapsed in order to ensure that any out-of-order events that come in for an old window can be processed as long as the grace period is active. Even for windows dramatically smaller than the grace period (e.g., a minute), we need to keep that level of granularity given the default 24-hour window.
In ksqlDB 0.23, we added the ability to specify a GRACE PERIOD in the WITHIN clause for stream-stream joins. The GRACE PERIOD clause will become mandatory in a future release and is only optional for now to ensure backward compatibility. Thus, we highly encourage you to use the GRACE PERIOD clause right away.
Here’s an example of a stream-stream-stream join that combines orders, payments, and shipments streams within a time interval and grace period. The resulting shipped_orders stream contains all orders paid within one hour of when the order was placed and shipped within two hours of the payment being received. Both joins specify a grace period of 30 minutes.
CREATE STREAM shipped_orders AS
SELECT
o.id as orderId
o.itemid as itemId,
s.id as shipmentId,
p.id as paymentId
FROM orders o
INNER JOIN payments p WITHIN 1 HOURS GRACE PERIOD 30 MINUTES ON p.id = o.id
INNER JOIN shipments s WITHIN 2 HOURS GRACE PERIOD 30 MINUTES ON s.id = o.id;
Semantic changes in left/outer joins with GRACE PERIOD
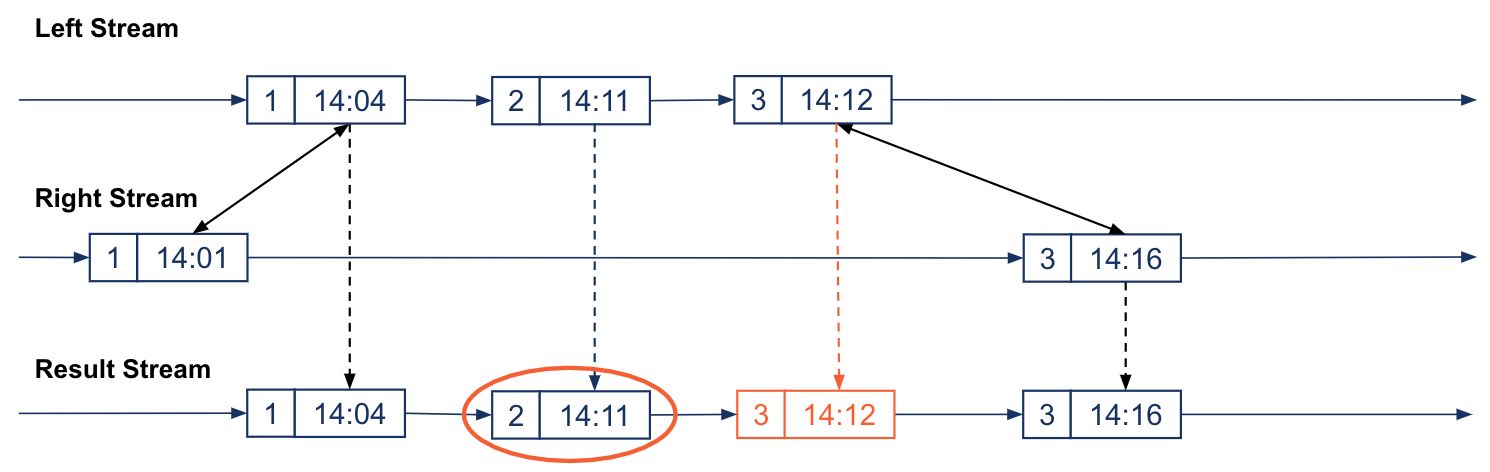
When a GRACE PERIOD is used in left/outer stream-stream joins, a new behavior is applied to the statement that changes the semantics of the join. In the past, when no GRACE PERIOD was used, non-joined records were emitted eagerly, which caused ”spurious” result records.
For instance, the image below shows a left/outer join that emits the non-joined record k: 2, ts: 14:11 from the left stream as soon as it is seen in the stream and before the end of the window. Similarly, it eagerly emits the spurious non-join record k: 3, ts: 14:12; the result is spurious because the left record actually joins with the right record k: 3, ts:14:13 later.
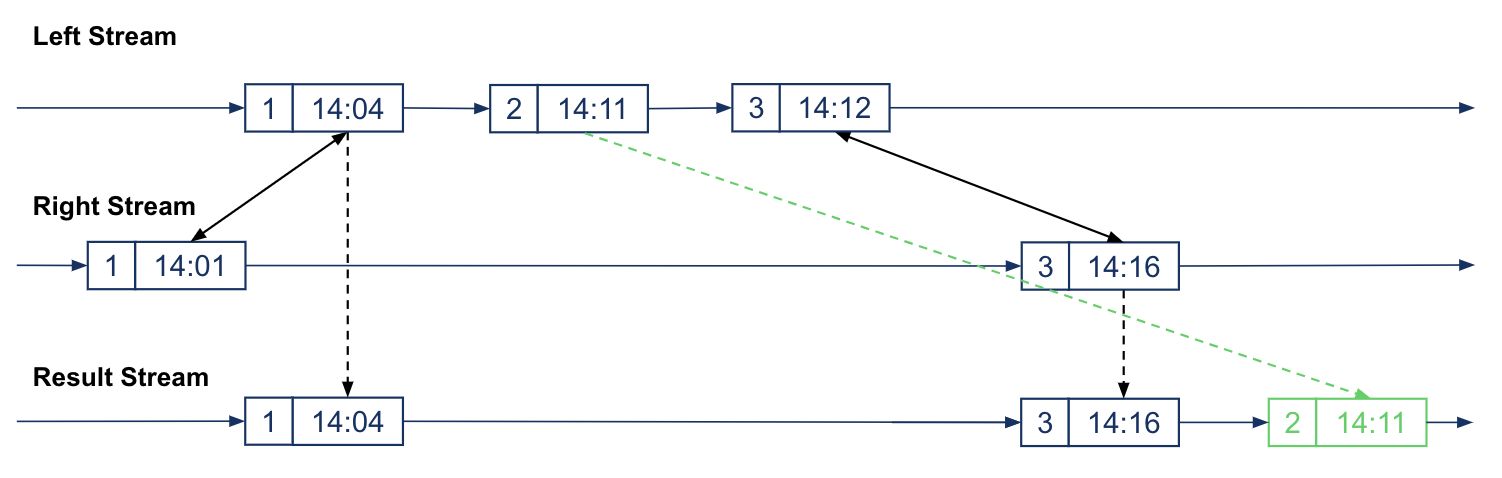
In ksqlDB 0.23, if you specify a GRACE PERIOD, the grace period defines when the left/outer join result is emitted. Now, a non-joined record will be emitted only after the grace period has passed, thus giving you better results of joined and non-joined records in a window.
For instance, the image below shows the same non-joined record k: 2, v: 14:11 emitted after the window has completed. More importantly, there is no spurious non-joined result for k=3 because when the inner join for k=3 is done we know that we don’t need to emit a non-joined record for k=3 when the window closes.
If you want to learn more about the new syntax and other stream-stream joins semantics, refer to the documentation on joins.
Get started with ksqlDB
Get started with ksqlDB today, via the standalone distribution or with Confluent, and join the community to ask questions and find new resources.
Avez-vous aimé cet article de blog ? Partagez-le !
Abonnez-vous au blog Confluent



Why ELT Can't Keep Up in the Era of High-Scale Data Engineering
Batch ELT pipelines create duplication, cost spikes, and governance gaps as data scales. Here’s why enterprises are rethinking legacy integration models.



How to Protect PII in Apache Kafka® With Schema Registry and Data Contracts
Protect sensitive data with Data Contracts using Confluent Schema Registry.