[Virtual Event] Agentic AI Streamposium: Learn to Build Real-Time AI Agents & Apps | Register
Announcing ksqlDB 0.22.0
We’re pleased to announce ksqlDB 0.22.0! This release includes source streams and source tables as well as improved pull query (for key-range predicates) and push query performance. All of these features are now available in Confluent Cloud. We’re excited to share them with you, and we will cover the most notable changes in this blog post. Check out the changelog for a complete list of features and fixes.
Execute pull queries instantly with SOURCE tables
Prior to ksqlDB 0.22, pull queries were limited to tables that were created with a CREATE TABLE AS SELECT (CTAS) statement. As you may know, a CTAS statement executes a long-running Kafka Streams job in the background that maintains an internal state store (RocksDB) for table state changes. ksqlDB uses these internal state stores to serve pull queries. In contrast, a CREATE TABLE (CT) statement is a metadata operation that defines the table schema. However, data is only stored in the underlying topic but is not pulled into a state store; hence, this is why they weren’t supported in the past (see the figure below).
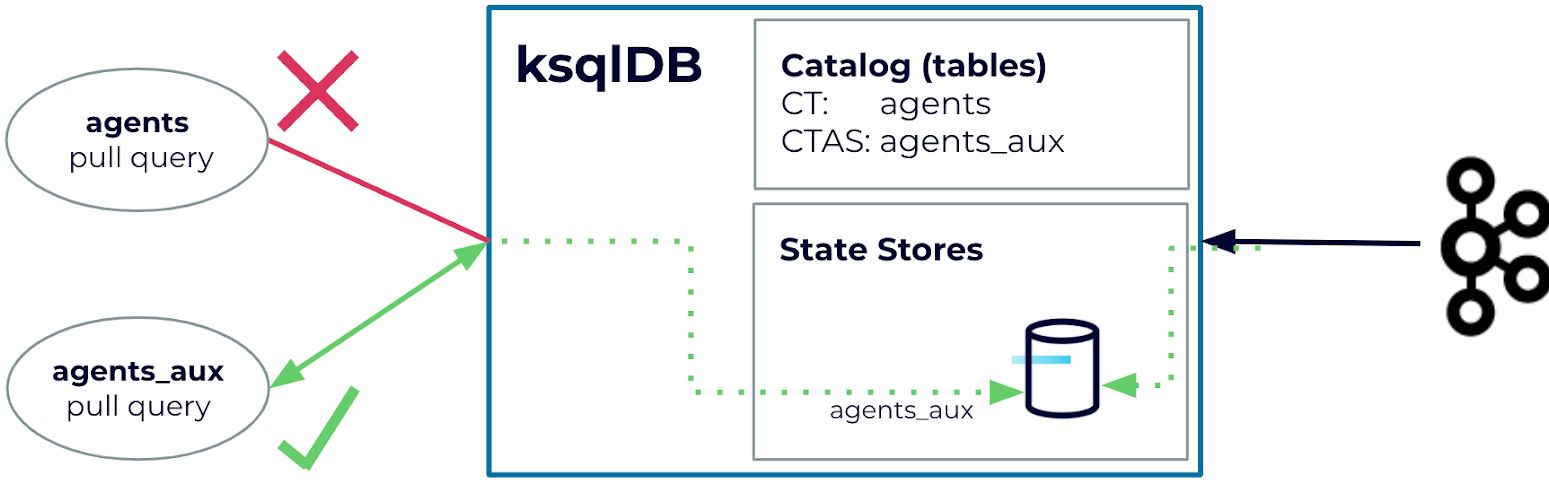
Because of the above requirement, if you want to look at topic content and query it using pull queries, you need to execute the following steps:
- Register your topic as a table
CREATE TABLE agents (id STRING PRIMARY KEY, name STRING) WITH (KAFKA_TOPIC=’agentsTopic’, FORMAT='JSON');
- Create a new table using the CTAS statement
CREATE TABLE agents_aux AS SELECT id, name FROM agents EMIT CHANGES;
- Issue pull queries on the new table
ksql> SELECT id, name FROM agents_aux WHERE id = ‘007’; +-----------------------+-----------------------------------+ |ID |NAME | +-----------------------+-----------------------------------+ |007 |James Bond | Query terminated
These steps are a hassle if you have several tables that must be queryable with pull queries.
In ksqDB 0.22, we reduced the above steps by introducing the concept of source tables. A source table allows you to instantly run pull queries on tables without the need for an auxiliary CTAS statement, thus reducing the number of steps that you need to immediately start looking at the data of a topic.
Source tables are created by using the SOURCE keyword in the CREATE TABLE statement.
CREATE SOURCE TABLE agents (id STRING PRIMARY KEY, name STRING) WITH (KAFKA_TOPIC=’agentsTopic’, FORMAT='JSON');
ksql> SELECT id, name FROM agents WHERE id = ‘007’; +-------------------------------+-----------------------------------+ |ID |NAME | +-------------------------------+-----------------------------------+ |007 |James Bond | Query terminated
Source tables share the behavior of a CTAS statement where an internal state store (RocksDB) is created and maintained in order to provide pull queries capabilities.
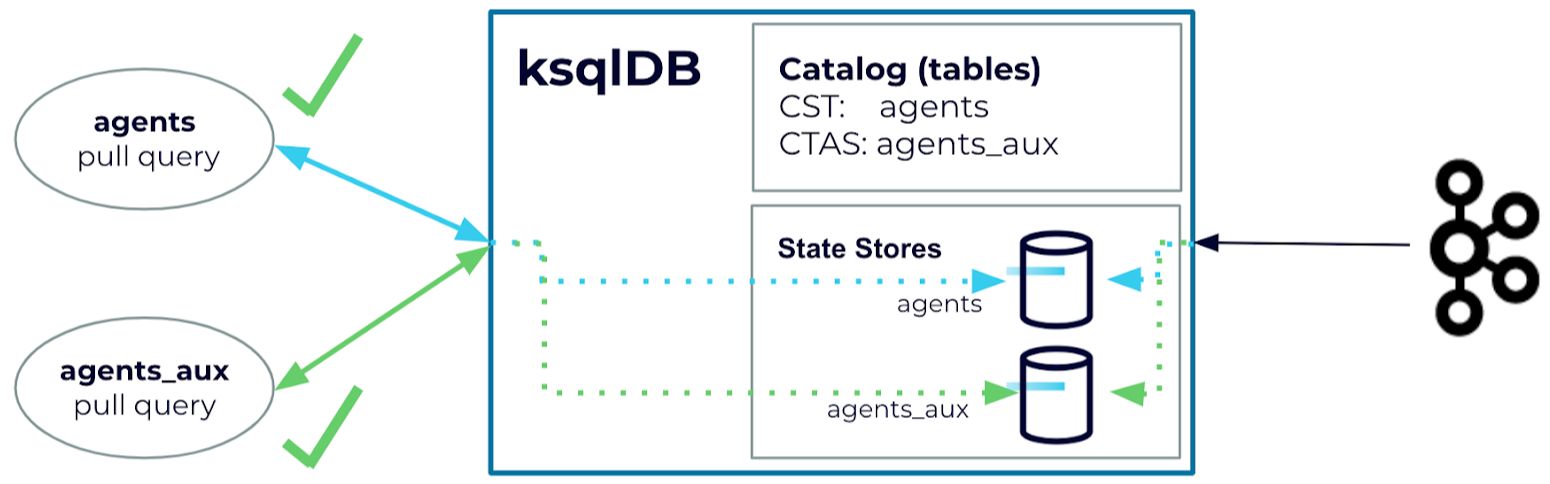
The SOURCE keyword also makes the table read-only, which is useful when you process data from upstream topics you don’t own and want to protect from modifications. You can also create read-only streams applying the SOURCE keyword when defining a stream: CREATE SOURCE STREAM <schema> WITH(...). Because source streams/tables are read-only and should be used for topics you don’t own, INSERT statements and DROP ... DELETE TOPIC statements are not supported. This is also true for tables created with CTAS statements that are marked as read-only.
Optimizations for range-scan expressions
Before this release of ksqlDB, pull queries with a WHERE clause using a range expression were implemented as full table scans, that is, all the records from a table were retrieved from the state store and then filtered within ksqlDB. With the 0.22 release, range queries on the primary key are now optimized to retrieve the exact range of records from the underlying state store, which is both faster–because no additional filtering is needed–and also more efficient in terms of I/O.
To illustrate the performance advantage of the range-scan optimization we ran a benchmark on a table with 10 million rows. The schema of the stream and the materialized view are shown below:
CREATE STREAM riderLocations2str (profileId STRING, latitude DOUBLE, longitude DOUBLE) WITH (kafka_topic='locations', value_format='json', partitions=1);
CREATE TABLE t2str AS SELECT profileId, LATEST_BY_OFFSET(latitude) AS v1, LATEST_BY_OFFSET(longitude) AS v2 FROM riderlocations2str GROUP BY profileId EMIT CHANGES
We generated 10 million records with monotonically increasing (profile) keys and issued the following query retrieving a subset of all the records smaller than a certain threshold:
SELECT profileId, v1, v2 FROM t2str WHERE profileId < '${rangekey}';
The figure below illustrates the advantage of the range-scan optimization compared to non-optimized implementation based on table scans:
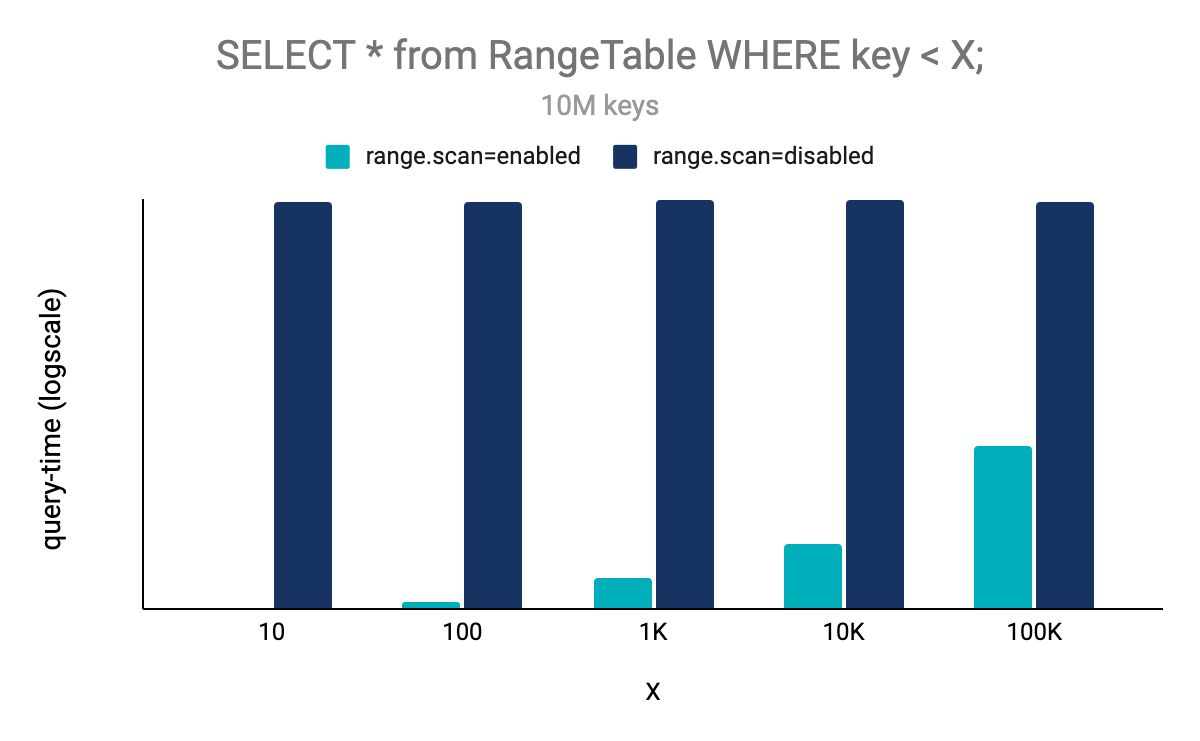
As expected, the less selective the query is, the bigger the advantage of the range-scan optimization becomes.
Improved push queries
Push queries allow you to subscribe to a SQL query for changes. Before this release of ksqlDB, each query required launching a Kafka Streams application. In ksqlDB 0.22.0, a subset of push queries can now utilize a new architecture that allows them to run within a shared Kafka Streams application, and thus can be executed much more efficiently than before.
Get started with ksqlDB
Get started with ksqlDB today, via the standalone distribution or with Confluent, and join the community to ask questions and find new resources.
Avez-vous aimé cet article de blog ? Partagez-le !
Abonnez-vous au blog Confluent



Why ELT Can't Keep Up in the Era of High-Scale Data Engineering
Batch ELT pipelines create duplication, cost spikes, and governance gaps as data scales. Here’s why enterprises are rethinking legacy integration models.



How to Protect PII in Apache Kafka® With Schema Registry and Data Contracts
Protect sensitive data with Data Contracts using Confluent Schema Registry.