[Virtual Event] Agentic AI Streamposium: Learn to Build Real-Time AI Agents & Apps | Register
Announcing ksqlDB 0.15
We’re pleased to announce ksqlDB 0.15, our first release of 2021! This version adds rich support for message key columns and long-awaited improvement to interactive development with the command line interface. We’ll step through these changes in detail, but please refer to the changelog for the complete list of features and fixes. If you just want to get started, the fastest way is through Confluent Cloud, which always runs the latest release of ksqlDB.
Expanded support for message keys
Many applications write records with complex message keys, typically serialized using a data format like Avro, Json, or Protobuf capable of storing structured data. In earlier versions of ksqlDB, users could only use the data in the key if the key was a primitive, like a STRING or BIGINT. In 0.15, ksqlDB now supports many more types of data in message keys to help you unleash the power of ksqlDB on data that you couldn’t access before. In particular, we’ve added support for:
- All supported serialization formats: JSON, AVRO, PROTOBUF, DELIMITED, KAFKA, and JSON_SR
CREATE STREAM my_stream (my_key BIGINT KEY, v1 STRING, v2 INT) WITH (KAFKA_TOPIC='my_topic',
KEY_FORMAT='PROTOBUF', VALUE_FORMAT='JSON');
- Structured data types, such as ARRAY, STRUCT, and nested combinations, in addition to previously supported types: STRING, INTEGER, BIGINT, DOUBLE, DECIMAL, and BOOLEAN
CREATE STREAM my_other_stream (
my_key STRUCT<f1 INT, f2 STRING> KEY, v1 STRING, v2 INT) WITH(KAFKA_TOPIC=’my_topic’, FORMAT=’JSON’);
Additionally, ksqlDB now supports PARTITION BY and GROUP BY clauses with multiple partitioning or grouping expressions, resulting in tables and streams with multiple key or primary key columns, respectively. This means you can now PARTITION BY multiple expressions (previously, this would raise a syntax error). You can also reference the resulting columns in subsequent queries.
CREATE STREAM my_repartitioned_stream AS
SELECT my_key->f1 AS k1, v1, AS k2, v2
FROM my_other_stream
PARTITION BY my_key->f1, v1
EMIT CHANGES;
CREATE TABLE my_aggregate AS
SELECT k1, k2, COUNT(*) AS cnt
FROM my_repartitioned_stream
GROUP BY k1, k2
EMIT CHANGES;
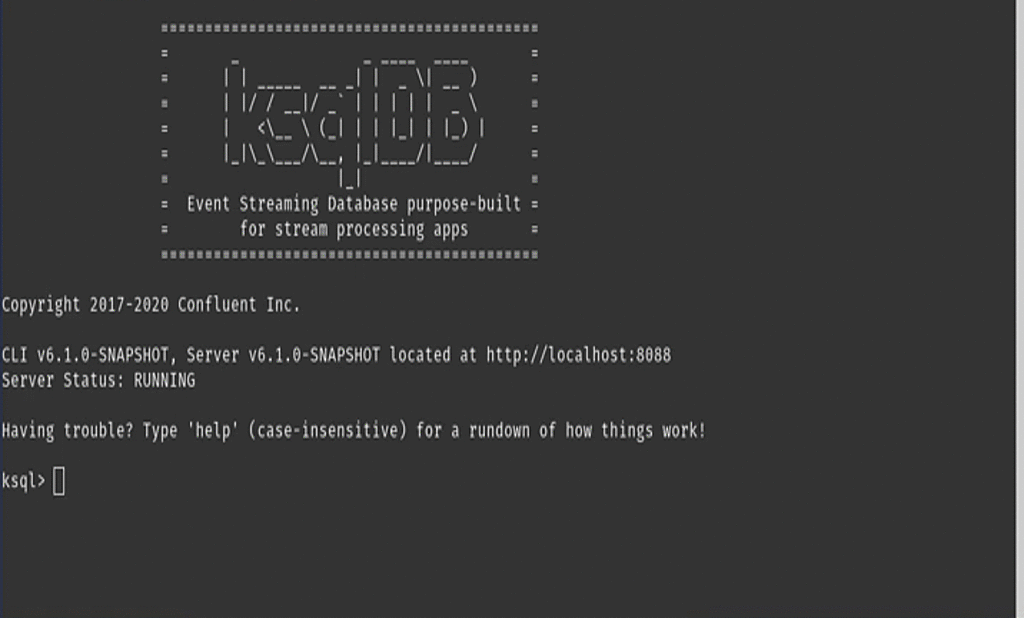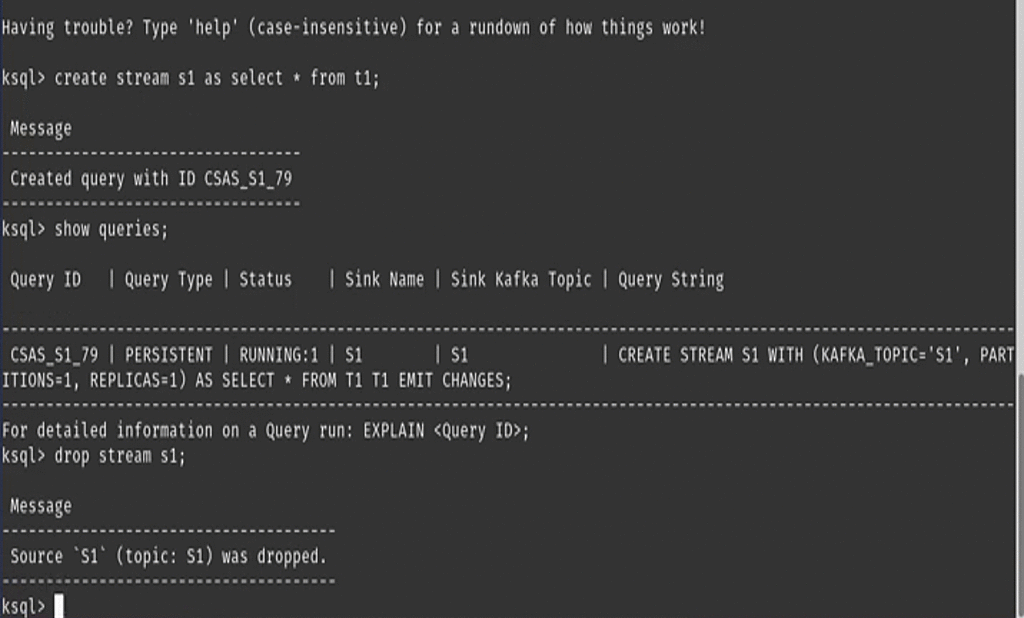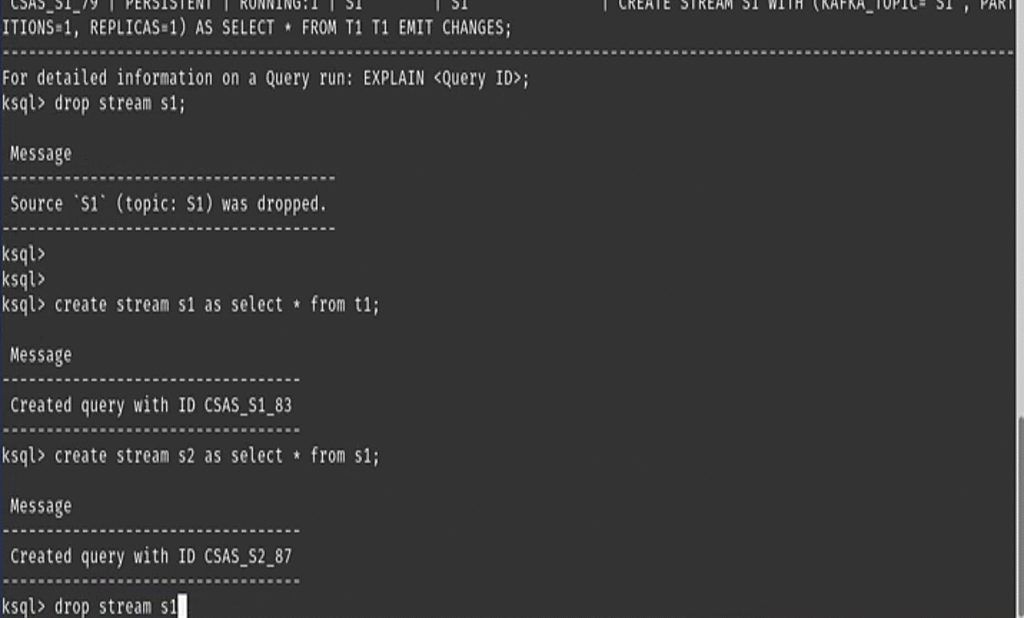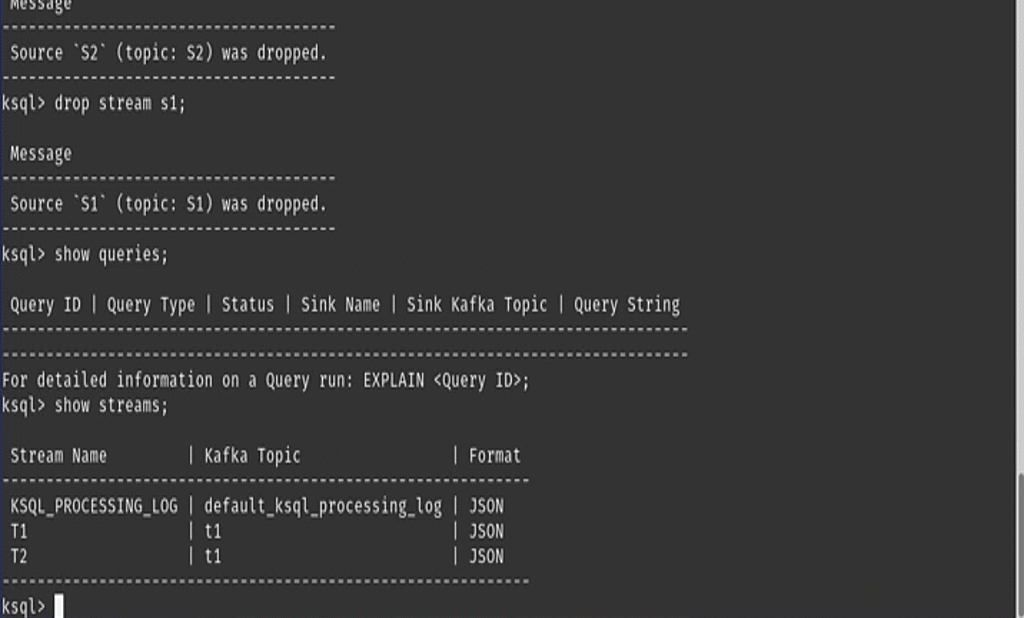
Terminate a persistent query on a DROP command
Up until this point, dropping a stream/table running a persistent query required two commands to delete the stream/table from ksqlDB: a TERMINATE command to stop and terminate the query, followed by a DROP command to delete the stream or table metadata. This was inconvenient because you had to know the query ID in advance to terminate it. Even writing SQL scripts had its complications, because query IDs are random and not easy to predict (e.g., TERMINATE CSAS_MYSTREAM_32).
To improve this, ksqlDB now terminates the persistent query of the stream/table automatically during the DROP command. You only need the stream/table name that you want to delete.
| ℹ️ | Note: As any other database system, if the stream or table you are trying to delete is used by other streams/tables or queries, then the DROP will not terminate the query nor drop the stream until all referenced streams and tables are deleted. |
Get started with ksqlDB
ksqlDB 0.15 includes many exciting new features, including expanded support for complex message keys and simpler semantics for DROP. For a full list of changes, you can review the release changelog.
To get started, try ksqlDB today via the standalone distribution or with Confluent Cloud, and check out the Confluent Community Forum to get involved with the community.
Avez-vous aimé cet article de blog ? Partagez-le !
Abonnez-vous au blog Confluent



Why ELT Can't Keep Up in the Era of High-Scale Data Engineering
Batch ELT pipelines create duplication, cost spikes, and governance gaps as data scales. Here’s why enterprises are rethinking legacy integration models.



How to Protect PII in Apache Kafka® With Schema Registry and Data Contracts
Protect sensitive data with Data Contracts using Confluent Schema Registry.