[Virtual Event] Agentic AI Streamposium: Learn to Build Real-Time AI Agents & Apps | Register
Introducing Cluster Linking in Confluent Platform 6.0
With the release of Confluent Platform 6.0 comes a preview of Confluent Cluster Linking available to self-managed customers and in Confluent Cloud for our early access partners. Cluster Linking is a new concept that defines a communications link between two independent Apache Kafka® clusters and introduces a new way to manage “mirrored” topics that traverse clusters. We’re excited to share the opportunities that Cluster Linking offers, how it enhances the Kafka architecture by advancing data protection and sharing capabilities, and a look into the future for upcoming improvements.
You can learn more about Confluent Cluster Linking in this video, which is part of Project Metamorphosis:
Re-envisioning topic mirroring
Replicating topics between Kafka clusters has been a long-standing problem that’s seen a number of solutions, including MirrorMaker and Confluent Replicator. Although the utility of these projects has come a long way, they’re not without their respective issues. At Confluent, we set out to reconsider what a truly easy and seamless cross-cluster topic replication experience would be, and we’re now ready to share our progress and vision.
We’ve engineered a solution that requires zero external components or services that mirrors topics to a remote cluster—replicating topic data partition for partition, byte for byte, as well as important metadata, making the read-only mirror (destination) topic naturally offset preserving and (almost) logically identical to its source. All that’s needed is to create a cluster link, which is a new named object that specifies the properties necessary to connect the source and destination clusters:
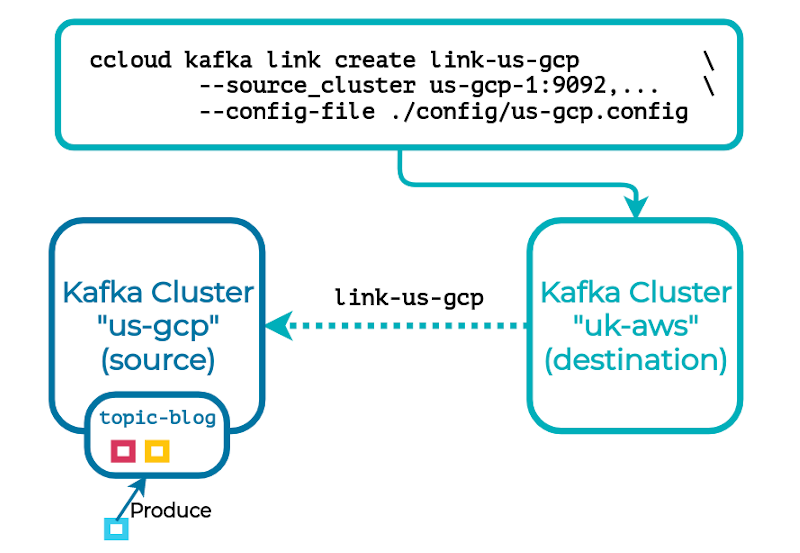
This is followed by a new topic that’s paired with the cluster link and the source topic’s name:
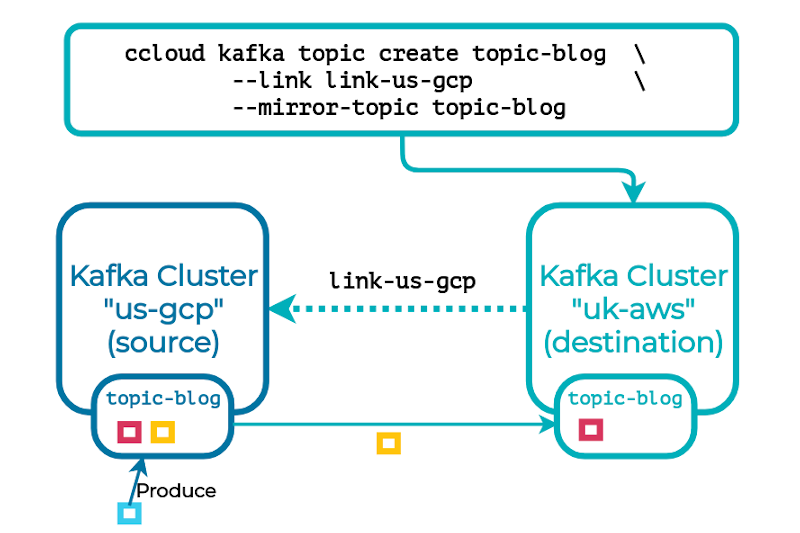
In the background, the mirror topic will begin replicating from its source topic over the cluster link. Once caught up, from a client’s perspective, the mirror topic should be nearly indistinguishable from its source.
Mirror topic replication is real time and continuous. It’s also performed asynchronously, which minimizes the impact on its source topic and doesn’t carry strict latency requirements between the clusters, permitting global replication. Both the source and mirror topics’ in-sync replica (ISR) sets are managed independently by their respective cluster to ensure no coupling between the topics. In its steady-state, a mirror topic should lag behind its source by no more than a couple of seconds to keep the recovery point low. In addition to data replication, a source topic’s configuration, consumer offsets, and ACLs can be mirrored to ensure state is kept in sync. At any point, mirroring can be stopped and the destination’s topic becomes a normal, mutable topic.
However, setting up mirror topics is just the beginning, because the process by which you operate and manage these topics should also be simple and intuitive, yet powerful enough to handle all situations and events—planned or unplanned—to ensure data and workload continuity. Cluster Linking unlocks a number of use cases that have otherwise carried restrictions or special handling, and we’ll explore how perfect topic mirroring enables seamless migration of topics across clusters, the ability to cloud-burst topics, and effective handling of disaster recovery scenarios.
Looking forward, operationally
Cluster Linking makes topic mobility easy. Imagine you’re in the process of expanding or migrating your operations, and you’ve created a new Kafka cluster that’ll be responsible for handling some of the existing topics. Regardless of whether this migration is from your on-premises cluster to Confluent Cloud, or from one cloud provider to another, as long as you’re running Confluent Server on the destination cluster, you’ll be able to link the clusters together.
Once topic mirroring has been established, replication will begin in the background, preserving the topics’ partition and consumer offsets as they’re created. Finally when replication has completed, the initial Cluster Linking release will enable you to “fail forward” your mirror topics, promoting them to independent, normal topics on the destination. Simply move your clients to your new cluster and resume their workload without any data reconciliation necessary.
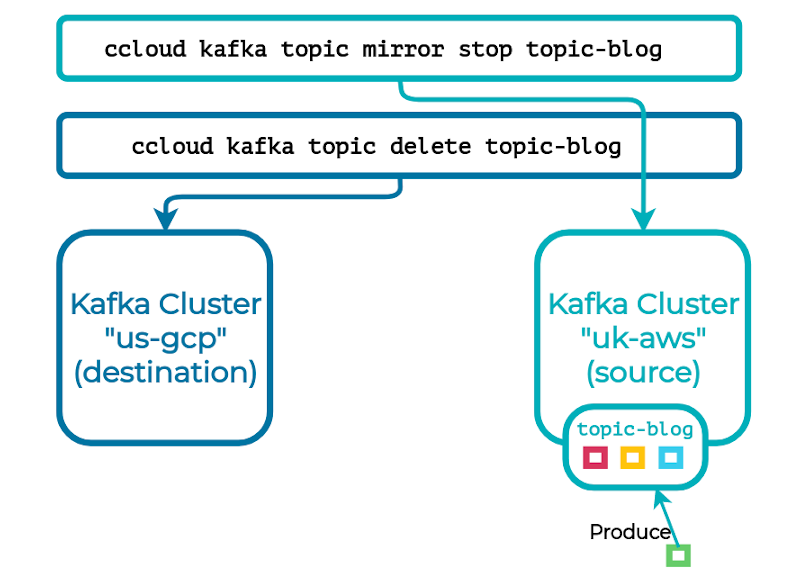
Looking forward, Cluster Linking will better support hybrid cloud scenarios. Let’s say you have a hybrid cloud Kafka setup, where your on-premises cluster has topics that you need to use in cloud, or vice versa. Your on-premises Confluent Platform cluster can cluster link to your Confluent Cloud cluster. Then, with a single mirror command, you can stream any relevant on-prem topic to cloud, and any relevant cloud topics can be imported on-prem. You’ll have a repeatable, secure, and reliable data highway to accomplish a hybrid cloud app, a temporary cloud burst, or a low-downtime and no-data-loss cloud migration.
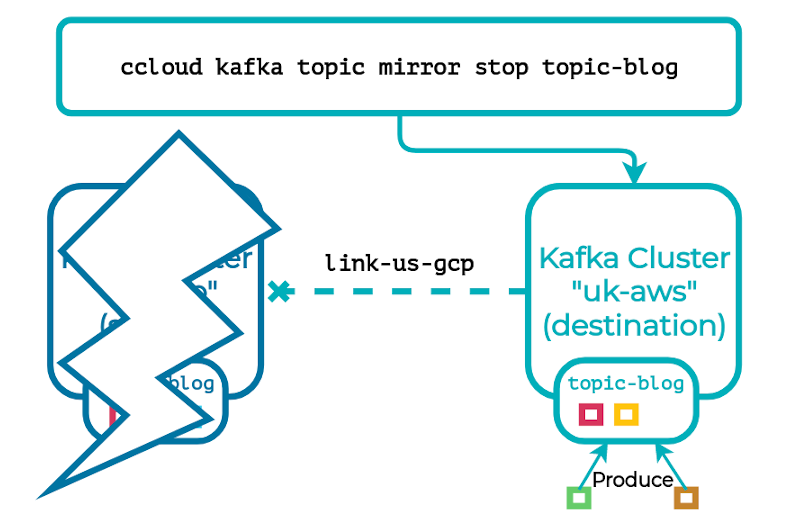
Cluster Linking can also protect your data from unplanned scenarios. Now let’s imagine you’ve set up Cluster Linking to mirror topics from your source cluster to your destination, but an unexpected event causes your source cluster to go down for an indefinite period. What can you do to mitigate the situation? By failing over to your mirror topics, which stops their replication and promotes them to normal topics, you can move your clients to your destination cluster and continue your workload. One caveat to note is that, because mirror topic replication is asynchronous, it’s possible that the mirror topics are behind; however in the steady-state healthy case, this gap should never be more than a couple of seconds.
Under the hood
It’s worth taking a quick look at how Cluster Linking and topic mirroring are designed to understand their power and simplicity. Since Kafka’s model for distributing data is to pull/fetch (as does a consumer or follower), the intuitive method chosen for replicating data across clusters is to have the destination cluster fetch from the source. This is where the cluster link comes in, as it contains the properties necessary for the destination cluster to communicate with the source.
Once created, the cluster link is persistent and can be referenced by its given name, and the destination cluster is now ready to create mirror topics that replicate from the source. By issuing a topic creation that specifies the cluster link and source topic’s name, a new mirror topic will be generated with the same number of partitions and topic configuration as the source. If, for example, new partitions are added to the source topic, the mirror topic will detect this and increase its own partitions to ensure that all data is captured and partition offsets are preserved.
As would a normal topic, a mirror topic’s partitions are distributed across the Kafka cluster’s brokers for leadership and ISR management. However, instead of accepting produce requests from clients, the partition leader recognizes that the partition is a mirror of another and continuously fetches records over the cluster link from the corresponding source partition, appending them to the local partition. Therefore, aside from disallowing produce requests, a mirror topic behaves and benefits from all of the functionality and improvements that’s present for normal topics.
Just the beginning
With Cluster Linking, we’re just beginning to explore the possibilities. There’s a variety of items on our roadmap that we look forward to presenting in the future. Of note are:
- Support for hybrid deployments where connections may only be initiated from the source cluster. Currently, connections originate from the destination cluster and therefore may not be able to connect with a source cluster due to networking rules. The introduction of smart links will allow the operator to specify which cluster is responsible for creating the connections.
- Continual iteration on the user experience, including clear and identifiable metrics to analyze a cluster link’s status, and a straightforward UI to provision and manage cluster links and their associated topics.
Ready to get started?
Cluster Linking is in early access on selected regions of Confluent Cloud and in preview in Confluent Platform 6.0.
You can also learn more about Cluster Linking in the documentation and try the demo.
Our wonderful team of distributed systems engineers and product managers helped bring Cluster Linking from a concept to a reality: Addison Huddy, Agam Brahma, Nikhil Bhatia, Raymond Ng, Sanjana Kaundinya, Tom Scott, and the entire Kafka team at Confluent.
Avez-vous aimé cet article de blog ? Partagez-le !
Abonnez-vous au blog Confluent



Empowering Customers: The Role of Confluent’s Trust Center
Learn how the Confluent Trust Center helps security and compliance teams accelerate due diligence, simplify audits, and gain confidence through transparency.



Unified Stream Manager: Manage and Monitor Apache Kafka® Across Environments
Unified Stream Manager is now GA! Bridge the gap between Confluent Platform and Confluent Cloud with a single pane of glass for hybrid data governance, end-to-end lineage, and observability.