Confluent named a Leader in the Forrester Wave: Streaming Data Platforms | Access the report
Project Metamorphosis Month 3: Infinite Storage in Confluent Cloud for Apache Kafka
This is the third month of Project Metamorphosis, where we discuss new features in Confluent’s offerings that bring together event streams and the best characteristics of modern cloud data systems. In the first two months, we talked about elasticity and cost. For this month, I’d like to talk about infinite storage for Apache Kafka®. Confluent Cloud CKUs today have storage limits, but not for long. Rolling out soon, all Standard and Dedicated Clusters will have no storage limits.
As enterprises become more digital and transition more towards real time, many companies realize the importance of having a centralized event streaming platform to handle the billions of interactions their customers have across their applications and services. Apache Kafka has become the standard for event streaming, but the typical setup is to store data in Kafka for days or weeks.
Why Infinite Storage for Kafka?
Kafka platform operators have needed to balance offering their developers longer data retention periods and their infrastructure costs—the longer the retention period the more hardware that is required. This is no longer a trade-off Kafka platform operators need to make in Confluent Cloud. Operators just pay for the data that is sent to Confluent Cloud and the system just scales. No pre-provisioning of storage, no waiting to scale, Confluent Cloud’s storage layer is truly infinite. Best yet, consumers that need more time to catch up (longer data retention times) don’t affect the performance of real-time clients.
The way Confluent Cloud storage now scales is a game-changer when it comes to operating a Kafka cluster, but why infinite?
I have talked to many Confluent customers over the years. Quite a few of them, after using Kafka for some time, started asking the question whether Kafka can be their system of record.
Within their enterprises, Kafka is often the very first point where all types of digitized data are integrated together. This integration effort is expensive, and you really just want to do it once. Therefore, Kafka is becoming the single source of truth for all other systems (data warehouse, search engine, monitoring systems, etc.) and applications that require this integrated digitized data. Those systems and applications typically obtain data from Kafka incrementally in real time. However, historical data, when combined with current information, can further increase the accuracy of insights and overall quality of customer experience. So, occasionally, those systems and applications may also need to access historical data.
The common practice today is to maintain historical data in a separate system and to direct the application to that system when historical data is needed. This adds complexity in that every application has to deal with an additional data source other than Kafka. Developers have to use two sets of APIs, understand the performance characteristics of two different systems, reason about data synchronization when switching from one source to the other, etc.
Imagine if the data in Kafka could be retained for months, years, or infinitely. The above problem can be solved in a much simpler way. All applications just need to get data from one system—Kafka—for both recent and historical data. What might this look like in practice?
- A retail bank wants to provide a better customer experience by allowing users to search all of their transactions online instead of just the last six months. This can be done by first integrating all transactional events in Kafka and then feeding the events from Kafka into a search engine like Elasticsearch. As new transactional events are added in Kafka, they will be incrementally reflected in the Elasticsearch index in real time. Occasionally, an existing Elasticsearch instance might fail and need to be replaced, or a new instance needs to be added to accommodate for the increased traffic. How do those new instances bootstrap with all existing transactions? Infinite retention in Kafka makes this easy. The Elasticsearch instance can just reset the consumer offset in Kafka to zero to catch up on all historical data. Once caught up, it seamlessly switches to the incremental mode. This is much simpler than using Kafka for the incremental part and another system for bootstrapping.
- Regulations require a financial institution to keep its data for seven years. When an investigation case is filed, new applications need to be built to access historical data. Kafka is ideal for the regulatory need since the events in Kafka are immutable. Infinite retention allows the financial institution to keep the data in Kafka for as long as it wants. The investigative applications can be built much more easily by feeding any historical data from Kafka.
- A ridesharing application powered by machine learning uses both real time as well as historical data for providing arrival time estimates. This can be done using stream processing libraries such as ksqlDB. ksqlDB stores its state in a local store for efficiency. If a ksqlDB instance is gone, the state of the instance needs to be rebuilt. Infinite retention allows ksqlDB to store the full commit log in Kafka and replay the log to rebuild its local state when necessary.
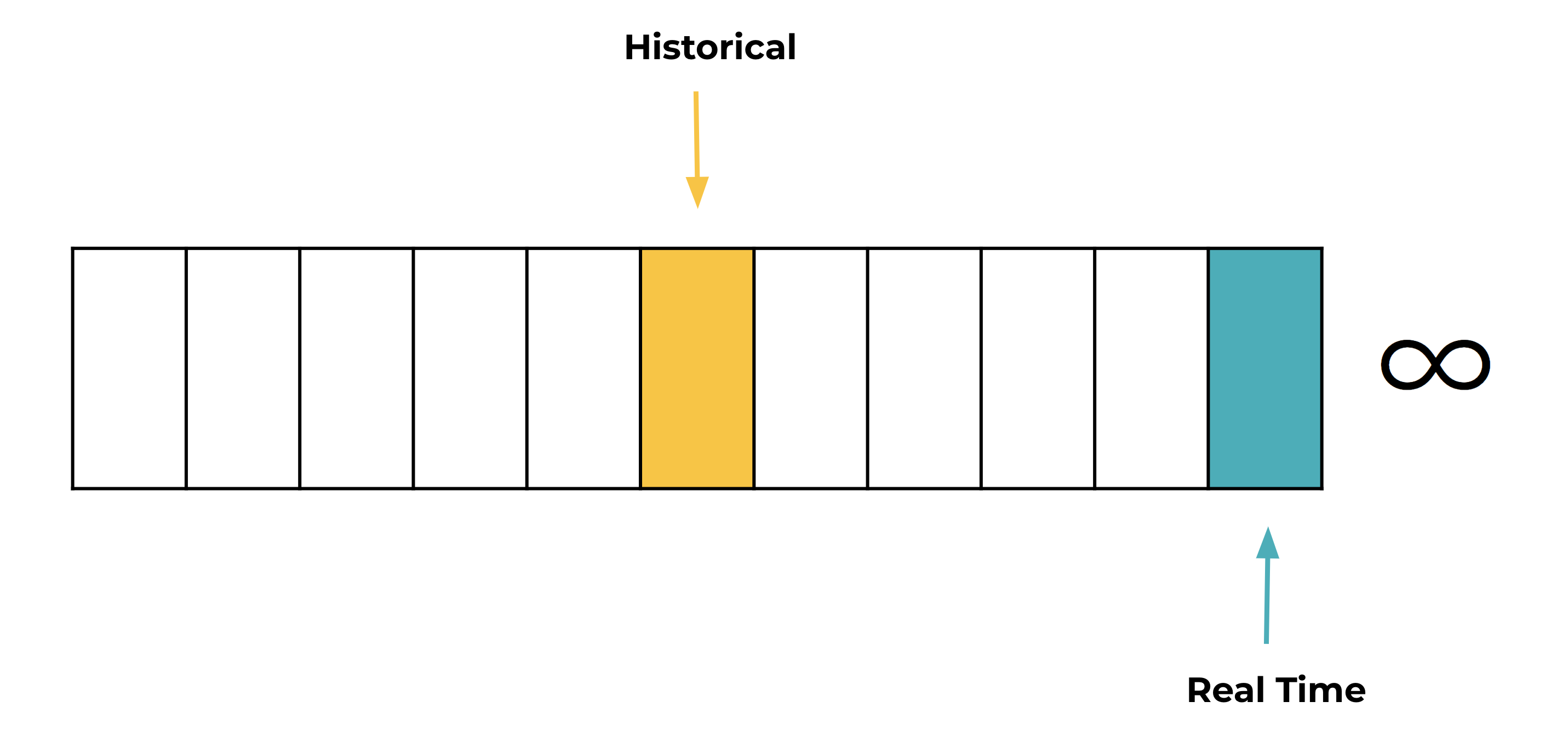
The nuts and bolts of Infinite Storage
Tiered Storage, which is in preview in Confluent Platform, was built upon innovations in Confluent Cloud, which is combined with various other performance optimization features to deliver on three non-functional requirements: cost effectiveness, ease of use, and performance isolation.
- Cost effectiveness: With the rollout of Infinite Storage, you won’t see any additional charges, provisioning units, nothing. We’ve decoupled storage resources from compute resources so you only pay for what you produce to Confluent Cloud. CKUs now don’t have storage limits.
- Ease of use: When using Tiered Storage in Confluent Platform, it requires tuning and administration. With Infinite Storage in Confluent Cloud, we’ve added performance optimization features that eliminate the need for tuning. Just create a topic with your desired retention period. You only pay for the storage that you use.
- Performance isolation: This is the most critical requirement. If an application is reading historical data, it won’t add latency to other applications reading more recent data. This characteristic of Confluent Cloud is what opens the door for real-time and historical analysis use cases in the same cluster.
What’s next?
If your organization has been using or is considering using Kafka, it would be useful to think through how infinite retention can help you. For example, could your existing architecture be simplified with Kafka being the system of record? Could new applications leverage both real time and historical data to provide a better user experience?
As I mentioned earlier, we’re enabling infinite retention in Confluent Cloud on AWS clusters in July, with the other cloud providers coming after. To get started, you can use the promo code CL60BLOG for $60 of additional free Confluent Cloud usage.* No pre-provisioning is required, and you pay for only the storage being used. Stay tuned for future announcements and watch the demo, which shows how you can scale from zero to 1 PB of data effortlessly with Confluent Cloud.
Avez-vous aimé cet article de blog ? Partagez-le !
Abonnez-vous au blog Confluent



Empowering Customers: The Role of Confluent’s Trust Center
Learn how the Confluent Trust Center helps security and compliance teams accelerate due diligence, simplify audits, and gain confidence through transparency.



Unified Stream Manager: Manage and Monitor Apache Kafka® Across Environments
Unified Stream Manager is now GA! Bridge the gap between Confluent Platform and Confluent Cloud with a single pane of glass for hybrid data governance, end-to-end lineage, and observability.