[Virtual Event] Agentic AI Streamposium: Learn to Build Real-Time AI Agents & Apps | Register
Hello World, Kafka Connect + Kafka Streams
Important: The information in this article is outdated. With recent Kafka versions the integration between Kafka Connect and Kafka Streams as well as KSQL has become much simpler and easier. See our articles Building a Real-Time Streaming ETL Pipeline in 20 Minutes and KSQL in Action: Real-Time Streaming ETL from Oracle Transactional Data.
This post was written by guest blogger Michal Haris, in collaboration with Neha Narkhede, Apache Kafka committer, Confluent Co-founder and CTO. Michal works in the digital media industry as a technical architect specializing in real-time big data infrastructure and proof-of-concept implementations of stream processing applications.
In the last few years, with the widespread adoption of Apache Kafka, stream processing has come to the forefront. More recently, several stream processing systems have emerged that integrate with Kafka. One of those systems, Apache Samza has a particularly interesting “hello world” tutorial for getting started with the system; Hello Samza, as it is called, uses Wikipedia real-time updates published on its IRC channels. In this post, we are going walk through the same tutorial but built using two new modules under the Apache Kafka project umbrella, one released recently and one planned for the upcoming release.
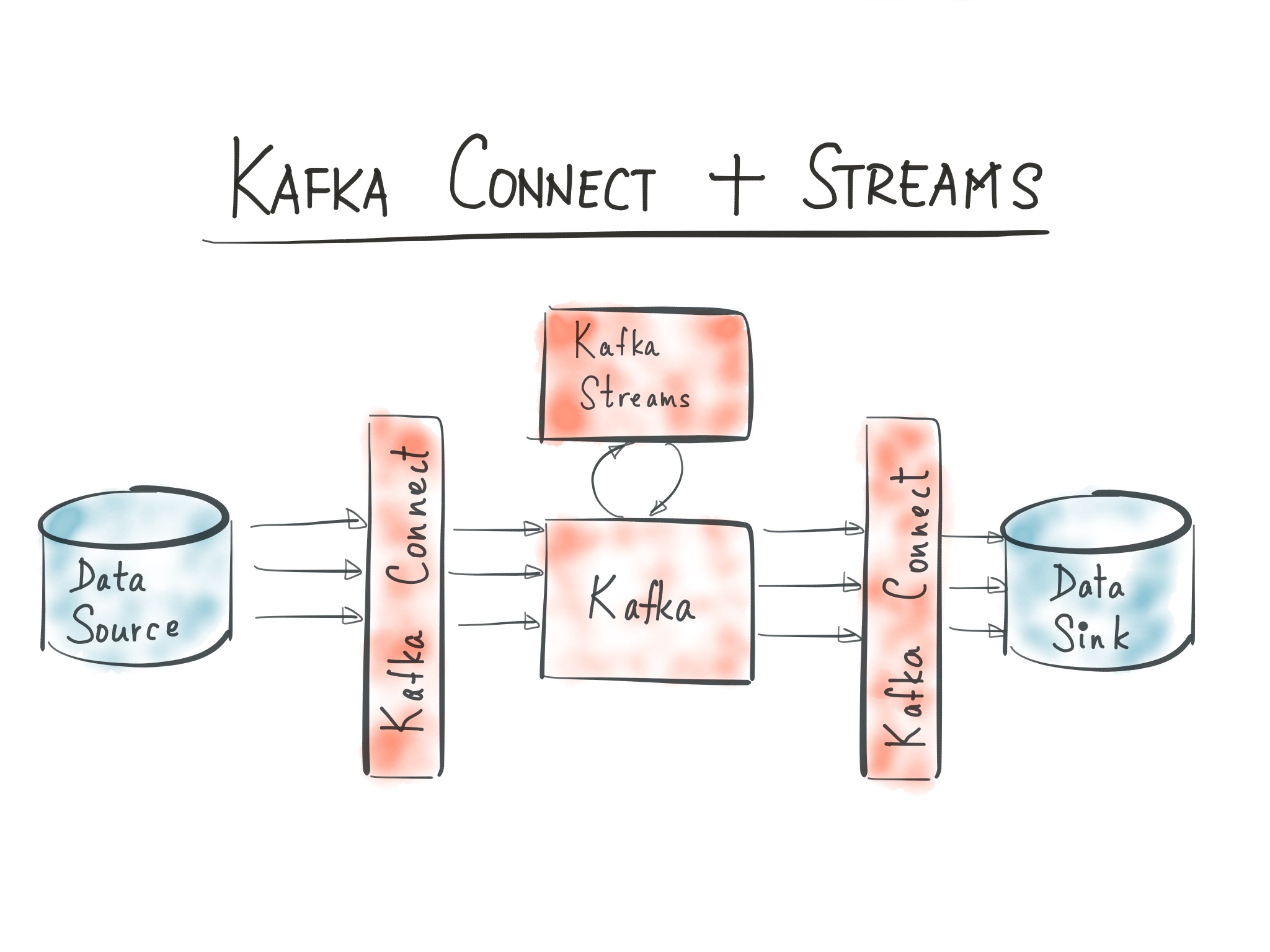 Released as part of Apache Kafka 0.9, Kafka Connect is a tool for scalably and reliably streaming data between Apache Kafka and other data systems. It offers an API, Runtime, and REST Service to enable developers to quickly define connectors that move large data sets into and out of Kafka. It comes with the fault-tolerance and elasticity we became accustomed to and was born out of the experience of an entire generation of ingestion and off-lading tools. Kafka Connect can ingest entire databases or collect metrics from all your application servers into Kafka topics, making the data available for stream processing with low latency. The release was announced in this article, where you can find links and more information.
Released as part of Apache Kafka 0.9, Kafka Connect is a tool for scalably and reliably streaming data between Apache Kafka and other data systems. It offers an API, Runtime, and REST Service to enable developers to quickly define connectors that move large data sets into and out of Kafka. It comes with the fault-tolerance and elasticity we became accustomed to and was born out of the experience of an entire generation of ingestion and off-lading tools. Kafka Connect can ingest entire databases or collect metrics from all your application servers into Kafka topics, making the data available for stream processing with low latency. The release was announced in this article, where you can find links and more information.
The other feature is Kafka Streams – a lightweight library for creating stream processing applications. It is lightweight in terms of deployment, in fact it is completely ‘weightless’ in that respect, unlike most, if not all, of its predecessors and contemporaries. The library is also lightweight since it builds on the primitives that are natively built within Kafka for problems that stream processing applications need to deal with — fault tolerance, partitioning, scalability, ordering, and load balancing. For those of us who value simplicity in software, it is a heavyweight champion, achieving so much with relatively little. More about the background and architecture here: Introducing Kafka Streams
In order to create our Hello Kafka Streams program, we need to connect Wikipedia IRC channels, turn them into a partitioned topic from which we can build our topology of processors. At the moment Kafka Connect doesn’t expose an embedded API, though all the necessary building blocks are already in place (under the connect-runtime module). The work is planned for future releases however, so we’ll fast forward by creating our own temporary extension in ConnectEmbedded.java.
Before we dive in, it is worth noting that there are two ways to run a connector to Kafka:
- As a connector on a cluster of processes that run Kafka Connect.
- As an embedded entity inside your application process.
You might wonder when it is a good idea to embed connectors in another process versus as a long-running process on a Kafka Connect cluster.
Connectors are better operated as long-running Kafka Connect processes for enabling streaming ETL flows between shared and standard data systems. For instance, extracting data from MySQL databases and loading it into Hadoop using the MySQL source connector and the HDFS sink connector. On the other hand, a connector that is only relevant to your application is more conveniently run as an embedded entity within your application’s processes. For instance, a demo application as described in this article. Here, we don’t want additional complexity to run services and manage connectors separately from our application just to run a simple demo application. Interestingly this is often the case in real-world applications and not just demos. Downscaling for development without changing the architecture is a much overlooked aspect of scalability – often we think only of upscaling to larger amounts of data or higher throughput.
Alright, without further ado, let’s jump straight into building Hello Kafka Streams.
If you’re familiar with the concepts and the APIs, you can skip the next section and just look at the whole project on GitHub.
NOTE: Since this demo builds on features that are part of the forthcoming 0.10.x release, you’ll either need Confluent Platform with the tech preview of Kafka Streams or Apache Kafka trunk or any 0.10.x version installed locally.
Wikipedia Demo on Kafka Streams – step by step
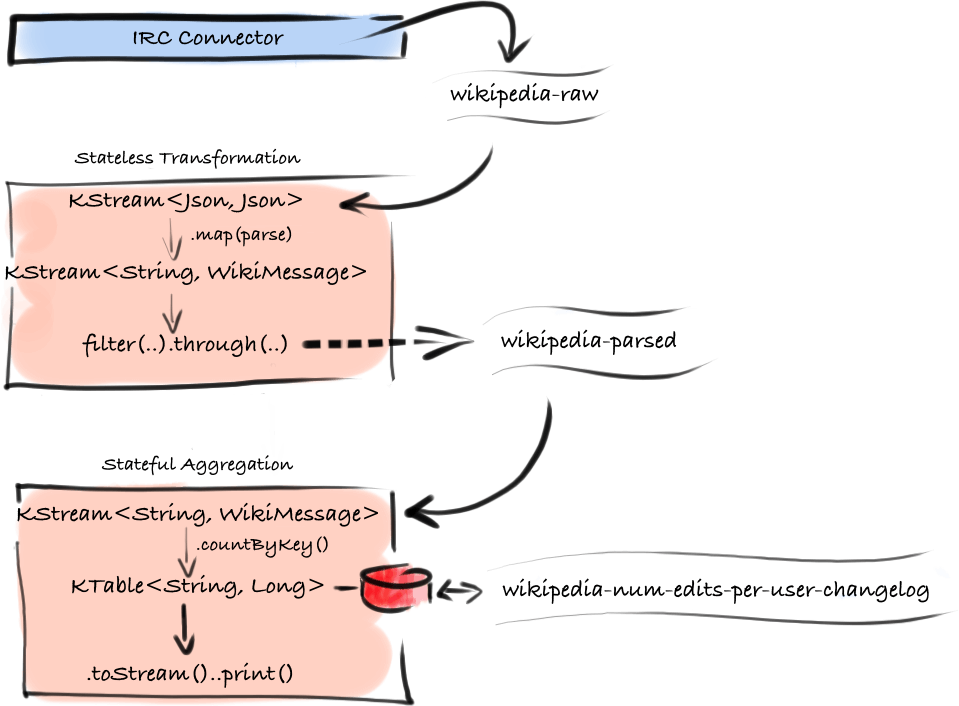
Above is an overview diagram of the integrated topology of connectors, topics, and processors.
First we need to introduce the generic IRC Connector. It is implemented in 3 classes here. The main class IRCFeedConnector takes an IRC host and port configuration, a list of channels, and an output topic. In the Kafka Connect design, connectors are serialization-agnostic. This allows them to be used in different context and if you, for example, have a Kafka Connect Service running and configured with Avro serializer, you could reuse this IRC Connector without modification by configuring it like this:
name=wikipedia-irc-source
connector.class=io.amient.kafka.connect.irc.IRCFeedConnector
tasks.max=10
irc.host=rc.wikimedia.org
irc.port=6667
irc.channels=#en.wikipedia,#en.wiktionary,#en.wikinews
topic=wikipedia-raw
In our main class, WikipediaStreamDemo, we provide this configuration programmatically in the method .createWikipediaFeedConnectInstance(). The result is the same – we will get at most 3 tasks, one for each channel, no matter how many instances of the application we run. Because we are starting an embedded instance, we have to also provide the worker configuration, converters, etc. To keep the demo concise we’re using org.apache.kafka.connect.json.JsonConverter which ships with Kafka and works automatically for any source schema thanks to the underlying design.
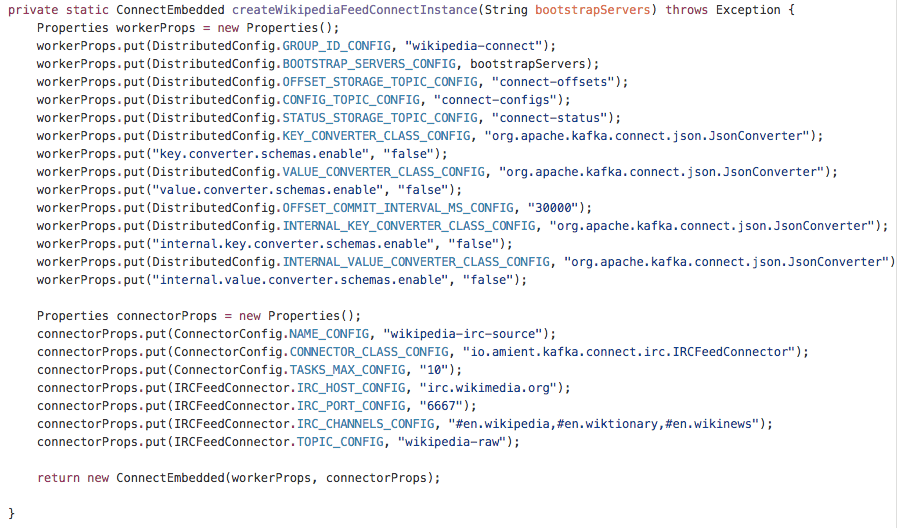
The Connect instance is configured, all that is left is to call method .start() and we’ve effectively integrated the connector into our application – we now have a coordinated group running in its own thread pool which ensures that the topic wikipedia-raw will be a stream of json representations of a generic IRCMessage from the wikipedia servers.
At this point we can have a look at the integrated topology defined in the .main(…) method which is really the only routine of the program, the rest is pretty much declarative.

After the connect instance is started, the streams topology is instantiated and started. The rest of the method just ensures that both services are stopped cleanly on shutdown. So the last remaining piece of code to look at is the method .createWikipediaStreamsInstance() where the Streams Topology is declared.

After creating instances of json serde helpers, we declare the first KStream<JsonNode, JsonNode> wikipediaRaw. Nothing other than picking up where we left with the connector.
In the next bit of code we declare a transformation on this json stream of wikipedia-raw messages, using method references of Java 8 for conciseness. The method .parseIRC() is what we’ve borrowed from the author of Hello Samza, to extract and parse the raw irc messages into WikipediaMessage.This method also changes the key of the transformed stream to the String username of the user submitting the edit which is necessary for correct per-user aggregation. Filter out any nulls that represent messages not understood by the parsers and what we’re left with is a stream of <String,WikipediaMessage> . This stream is persisted in the same statement into topic wikipedia-parsed using .through(..) method of KStream – using a generic jsonPOJOSerde<WikipediaMessage> we are saying that the content of this topic will also be json serialized. The key used for partitioning will be the username of the author as declared by the previous transformation.
At last a KTable<String, Long> is declared by filtering and aggregating the stream of parsed wikipedia message using .countByKey() – this is also our final output which is continuously prints the updates using lower-level .process() method.
Key Takeaways
So we have a complete stream processing application that pulls data from a public IRC server and computes some usage analytics. If you restart it, you’ll notice that it also remembers the last state of the counts per user – KTable is persisted in a changelog topic from which it is restored next time.
We’ll illustrate our earlier point about downscaling: we can now run one instance of hello-kafka-streams in a terminal and a second one in an IDE to debug how the instance behaves when it is part of the group – something chronically difficult to do in frameworks like YARN.
The fact that there is no deployment framework involved and all the instances are identical (including configuration, which is in this case literally burned into the main class) makes all deployment options available; your stream processing application remains unchanged whether you choose to package it in Docker and run it on Mesos or change from Chef to Puppet for configuration management.
One thing to note is that while the application is switched off there is nothing processing the IRC channels, which results in what can be viewed as data loss because the edits are not being counted. Any time a rebalance of work is happening in the connector group the same data loss occurs but that is simply a nature of IRC channels – if you’re offline you miss messages and there is no notion of offset in them. If you want a more loss-less variant of this demo the best you can do is minimize your application down time which is a topic perhaps for another post – or use a data source that has a notion of offset, at least a timestamp, and Kafka Connect will happily do the work of managing the last consumed offsets reliably.
As for the integration of Kafka Streams and Kafka Connect, there is a case for a first-class integration between the two in such a way that connector could map directly to a KStream which would allow applying any stream transformation directly on the output of the connector. In this wikipedia demo we could, for example, eliminate the wikipedia-raw topic and apply parsing and partitioning by username immediately, improving latency and the storage footprint without sacrificing any useful characteristic of the application.
First let’s look at one possible implementation. Here we reuse most of the existing code and introduce a new overload method .stream(…) on the stream builder which instead of topic name as the last argument takes an instance similar to the ConnectEmbedded except we’ll call it EmbeddedConnectSource:
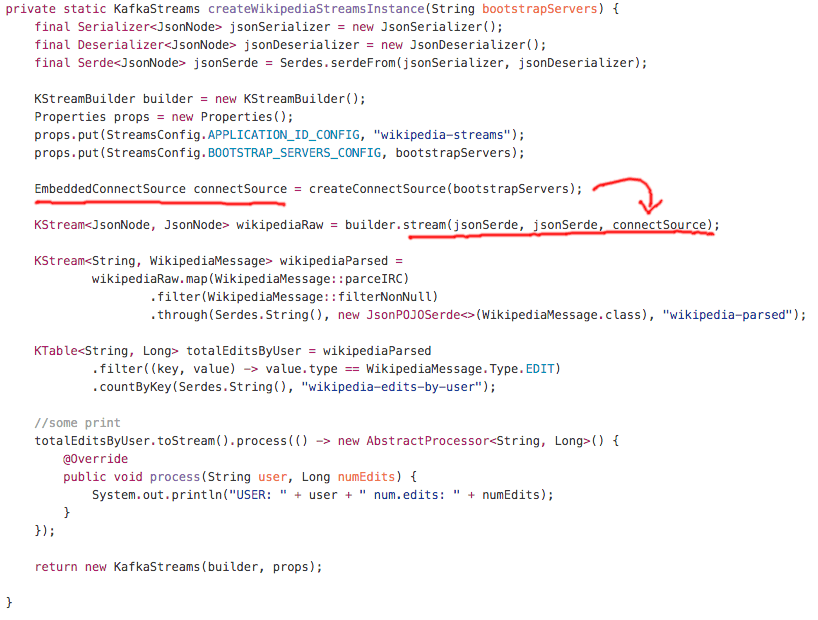
Above, method method createConnectSource() uses the same configuration as the method createWikipediaFeedConnectInstance() of our working demo solution. We are using JsonConverter which turns the source IRCMessage into serialized json. But notice, that right away we tell the stream builder to parse this serialized data back to JsonNode which is in turn deconstructed to WikipediaMessage. If you profiled this implementation you’re likely to find out that this conversion, parsing and deconstruction, is taking up most of the CPU cycles of the whole program.
More efficient version, where conversion to json and consequent parsing to JsonNode is avoided is if the stream builder is only given the connector config (not the worker config) and returns a stream of SchemaAndValue objects. This would require exposing some connector internals and is harder to implement at the Kafka side but saves cycles and is less noisy in terms of the initialization code for the applications:
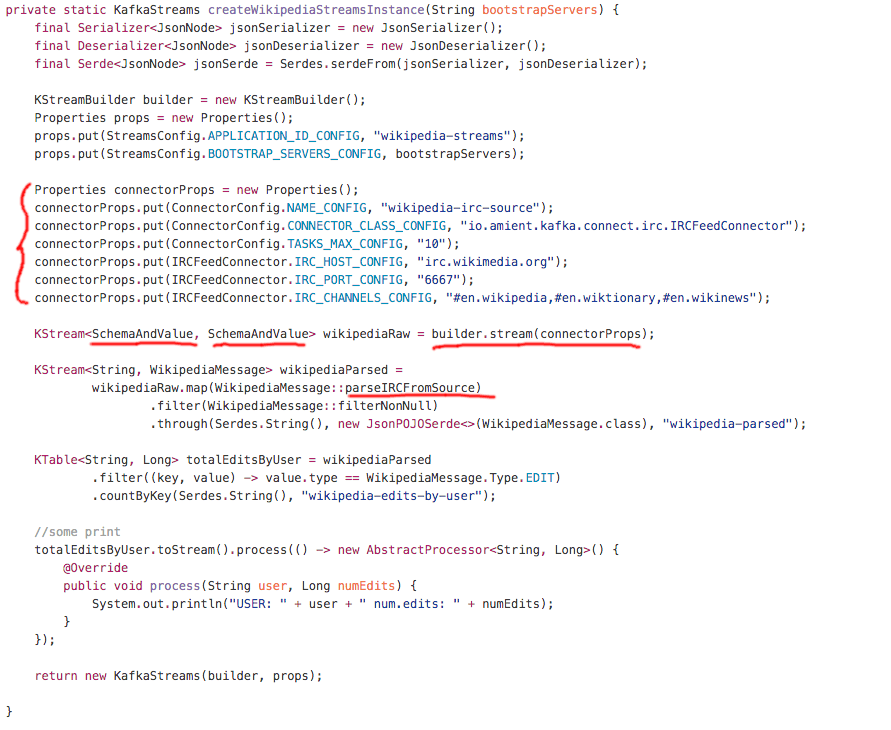 One way or the other, the integrated API is coming soon. Stay tuned!
One way or the other, the integrated API is coming soon. Stay tuned!
Conclusion
- Built on the right foundation: the fundamental primitives in Apache Kafka have proven successful and offer the right building blocks for implementing stream processing operations, be it real-time ingestion or stream processing. The resulting simplicity goes a long way in infrastructure tooling. The alternatives involve building and operating plugins to many disparate systems and thus are much less attractive compared to having a single platform at the heart of your datacenter.
- Approachable and developer friendly: It took about the same time (a day) to write the demo with Connect and Streams including the embedded runtime extension as it took to understand, package, and deploy the Hello Samza on a real cluster
- All-you-need: Using Kafka, Kafka Connect, and Kafka Streams together is not only possible but it delivers complete tooling for writing stream processing applications.
Avez-vous aimé cet article de blog ? Partagez-le !
Abonnez-vous au blog Confluent



Confluent Cloud for Government Achieves FedRAMP Moderate: Mission-Ready Data Streaming for Federal Agencies
Confluent Cloud for Government has achieved FedRAMP Moderate authorization, allowing federal, state, and local agencies to deploy secure, fully managed data streaming. By eliminating the operational burden of self-managed Kafka, the platform helps agencies break down data silos, modernize legacy...



Confluent Recognized in 2025 Gartner® Magic Quadrant™ for Data Integration Tools
Confluent is recognized in the 2025 Gartner Data Integration Tools MQ. While valued for execution, we are running a different race. Learn how we are defining the data streaming platform category with our Apache Flink® service and Tableflow to power the modern real-time enterprise.