[Virtual Event] Agentic AI Streamposium: Learn to Build Real-Time AI Agents & Apps | Register
Getting Started with the MongoDB Connector for Apache Kafka and MongoDB
Together, MongoDB and Apache Kafka® make up the heart of many modern data architectures today. Integrating Kafka with external systems like MongoDB is best done though the use of Kafka Connect. This API enables users to leverage ready-to-use components that can stream data from external systems into Kafka topics, as well as stream data from Kafka topics into external systems.
The official MongoDB Connector for Apache Kafka is developed and supported by MongoDB engineers. It is also verified by Confluent, following the guidelines set forth by Confluent’s Verified Integrations Program. The connector, now released in beta, enables MongoDB to be configured as both a sink and a source for Apache Kafka.
Getting started
In the next sections, we will walk you through installing and configuring the MongoDB Connector for Apache Kafka followed by two scenarios. First, we will show MongoDB used as a source to Kafka, where data flows from a MongoDB collection to a Kafka topic. Next, we will show MongoDB used as sink, where data flows from the Kafka topic to MongoDB.
To get started, you will need access to a Kafka deployment with Kafka Connect as well as a MongoDB database. The easiest and fastest way to spin up a MongoDB database is to use the managed MongoDB service MongoDB Atlas. No more fumbling around with provisioning servers, writing config files, and deploying replica sets—simply pick a cloud provider, a cluster size, and get a connection string!
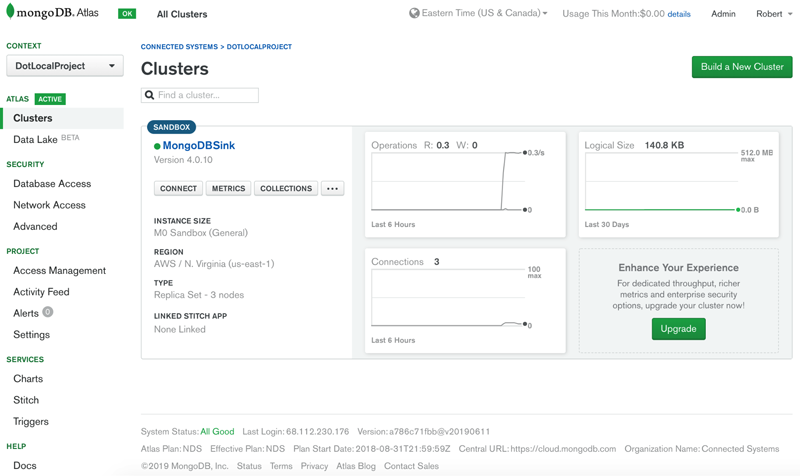
Figure 1. Free MongoDB Atlas cluster
If you do not have a MongoDB Atlas database, you can easily provision one by visiting MongoDB Cloud Services and clicking “Get started free.” For a detailed walkthrough of creating a MongoDB Atlas cluster, see the documentation.
You can use Confluent’s Docker images for a combined setup of Apache Kafka and Kafka Connect.
Install the MongoDB Connector for Apache Kafka
At this point, you should have access to a MongoDB database and Kafka deployment. Follow these instructions to install the MongoDB connector from the Confluent Hub.
You will need your connection string to MongoDB in order to configure the connector. To obtain the connection string in MongoDB Atlas, click on the “Connect” button for your MongoDB cluster. This will show a page with connection strings that are premade for any driver combination. For the MongoDB connector, use Java and version 3.4 or later. Copy the “Connection String Only” and use that for the connection.url in the MongoSinkConnector.properties file. Be sure to replace the <password> template with your actual password for this account. Note: if your password includes the @ symbol, use percent encoding.
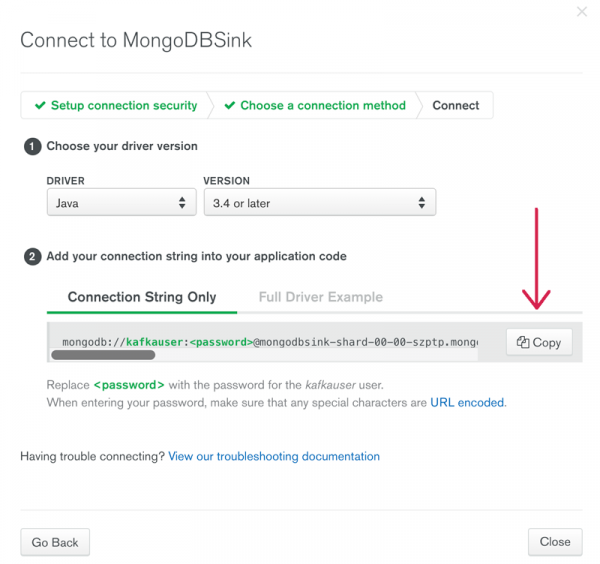
Figure 2. Connect page in MongoDB Atlas
Using MongoDB as a source to a Kafka topic
Consider the use case of an ecommerce website where the inventory data is stored in MongoDB. When the inventory of any product goes below a certain threshold, the company would like to automatically order more product. Ordering is done by other systems outside of MongoDB, and using Kafka as the platform for such event-driven systems is a great example of the power of MongoDB and Kafka when used together.
Let’s set up the connector to monitor the quantity field and raise a change stream event when the quantity is less than five. Under the covers, the connector is using MongoDB change streams, and the pipeline parameter defines the filter used to generate the event notifications.
curl -X PUT http://localhost:8083/connectors/source-mongodb-inventory/config -H "Content-Type: application/json" -d '{
"tasks.max":1,
"connector.class":"com.mongodb.kafka.connect.MongoSourceConnector",
"key.converter":"org.apache.kafka.connect.storage.StringConverter",
"value.converter":"org.apache.kafka.connect.storage.StringConverter",
"connection.uri":"<>",
"database":"BigBoxStore",
"collection":"inventory",
"pipeline":"[{\"$match\": { \"$and\": [ { \"updateDescription.updatedFields.quantity\" : { \"$lte\": 5 } }, {\"operationType\": \"update\"}]}}]",
"topic.prefix": ""
}'
In the example above, we provided a pipeline as a parameter. This defines the criteria for documents that are to be consumed by the connector. Since the pipeline contains quotations, we need to escape these so they work with our curl statement. For clarity, the pipeline value is as follows:
[
{
"$match": {
"$and": [
{
"updatedDescription.updatedFields.quantity": {
"$lte": 5
}
},
{
"operationType": "update"
}
]
}
}
]
For simplicity, here we use org.apache.kafka.connect.storage.StringConverter. However, the Kafka Connect framework lets us interchange whatever converter we’d like, such as Avro which enables rich schema support when using Kafka. Integrating schemas between MongoDB and Confluent Platform will be documented for our GA release.
For a complete list of the connector configuration options, check out the documentation.
To test out our scenario, we will use the open source tool kafkacat. The parameters below tell the tool to connect to the BigBoxStore.inventory topic as a Kafka consumer.
kafkacat -b localhost:9092 -t BigBoxStore.inventory -C
Next, we want to connect to the MongoDB cluster and update the inventory of an item in the inventory collection:
db.inventory.insert ( { “SKU” : 1, “item_name”:”Tickle Me Elmo”, “quantity” : 10 }
Now, imagine the holiday season is here. Tickle Me Elmo has made a comeback, and it is flying off the shelves. The backend inventory updates the quantity as follows:
db.inventory.updateOne({"SKU":1},{ $set: { "quantity" : 2} } )
If you look at the kafkacat output, you will see that the change stream event made it into the Kafka topic:
{
"_id": {
"_data": "825D1640BF000000012B022C0100296E5A1004E407DAB9B92B498CBFF2B621AAD032C046645F696400645D163AA63827D21F38DA958E0004"
},
"operationType": "update",
"clusterTime": {
"$timestamp": {
"t": 1561739455,
"i": 1
}
},
"ns": {
"db": "BigBoxStore",
"coll": "inventory"
},
"documentKey": {
"_id": {
"$oid": "5d163aa63827d21f38da958e"
}
},
"updateDescription": {
"updatedFields": {
"quantity": 2.0
},
"removedFields": []
}
}
With this message in the Kafka topic, other systems can be notified and process the ordering of more inventory to satisfy the shopping demand for Elmo.
Using MongoDB as a sink from a Kafka topic
In continuation of the ecommerce scenario, consider that when a new user is created on the website, their contact information is needed by multiple business systems. Contact information is placed in the Kafka topic newuser for shared use, and we then configure MongoDB as a sink to the Kafka topic. This allows new users’ information to propagate to a users collection in MongoDB. To configure the connector for this scenario, we can issue a REST API call to the connector service as follows:
curl -X PUT http://localhost:8083/connectors/sink-mongodb-users/config -H "Content-Type: application/json" -d ' {
"connector.class":"com.mongodb.kafka.connect.MongoSinkConnector",
"tasks.max":"1",
"topics":"newuser",
"connection.uri":"<>",
"database":"BigBoxStore",
"collection":"users",
"key.converter":"org.apache.kafka.connect.json.JsonConverter",
"key.converter.schemas.enable":false,
"value.converter":"org.apache.kafka.connect.json.JsonConverter",
"value.converter.schemas.enable":false
}'
To test our scenario, let’s use kafkacat to push a message that simulates the inventory system saying there is more inventory:
kafkacat -b localhost:9092 -t newuser -P <
To confirm that the message made it all the way through to your MongoDB database, make a connection to MongoDB using your client tool of choice and issue a db.users.find() command. If you’re using MongoDB Atlas, you can click on the “Collections” tab to show the databases and collections that are in your cluster.
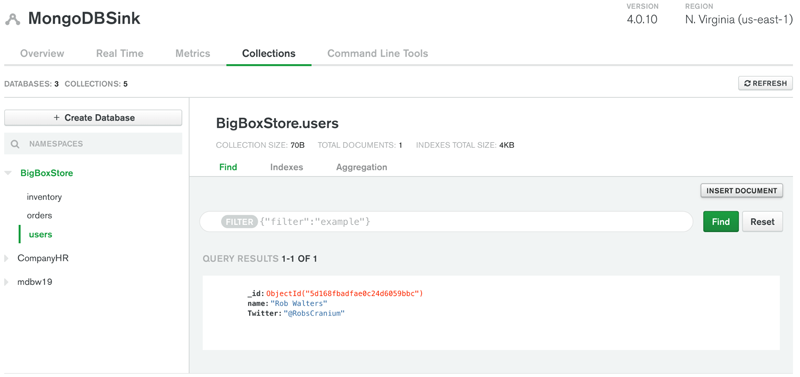
Figure 3. “Collections” tab in MongoDB Atlas
Summary
MongoDB is the world’s most popular modern database built for handling massive volumes of heterogeneous data, and Apache Kafka is the world’s best distributed, fault-tolerant, high-throughput event streaming platform. Together they make up the heart of many modern data architectures today. The MongoDB Connector for Apache Kafka is the official Kafka connector. The sink connector functionality was originally written by Hans-Peter Grahsl and with his support has now been integrated into MongoDB’s new source and sink connector, officially supported and maintained by the creators of MongoDB. This connector opens the door to many scenarios ranging from event-driven architectures to microservices patterns.
To learn more, you can also check out this reference architecture for MongoDB and Confluent Platform.
Avez-vous aimé cet article de blog ? Partagez-le !
Abonnez-vous au blog Confluent



From Dumb Pipes to a Smart Data Plane: Introducing Schema IDs in Apache Kafka® Headers
Confluent’s Schema IDs in headers transform Kafka from "dumb pipes" to a "smart data plane." By moving metadata out of payloads, teams can schematize topics without breaking legacy apps or requiring big-bang migrations. This unlocks governed, AI-ready data for Flink and lakehouses with ease.


Queues for Apache Kafka® Is Here: Your Guide to Getting Started in Confluent
Confluent announces the General Availability of Queues for Kafka on Confluent Cloud and Confluent Platform with Apache Kafka 4.2. This production-ready feature brings native queue semantics to Kafka through KIP-932, enabling organizations to consolidate streaming and queuing infrastructure while...