[Virtual Event] Agentic AI Streamposium: Learn to Build Real-Time AI Agents & Apps | Register
Distributed Consensus Reloaded: Apache ZooKeeper and Replication in Apache Kafka
This post was jointly written by Neha Narkhede, co-creator of Apache Kafka, and Flavio Junqueira, co-creator of Apache ZooKeeper.
Many distributed systems that we build and use currently rely on dependencies like Apache ZooKeeper, Consul, etcd, or even a homebrewed version based on Raft [1]. Although these systems vary on the features they expose, the core is replicated and solves a fundamental problem that virtually any distributed system must solve: agreement. Processes in a distributed system need to agree on a master, on the members of a group, on configuration, on the owner of a lock, and on when to cross a barrier. These are all problems commonly found in the design of distributed systems, and the approach of adopting one of these dependencies has been successful because these systems fundamentally solve the distributed consensus problem [2]. Having access to a consensus implementation enables distributed systems to coordinate processes in a more effective (but not necessarily transparent) manner, e.g., when managing the replicas sets of Kafka. In this post, we focus precisely on how such systems typically expose consensus and where it makes a difference in the replication scheme of Apache Kafka as a representative example.
Systems solving consensus at their core have been often called “consensus services”. The name “consensus service”, however, is possibly a poor choice of a name because none of those services actually exposes a way of solving consensus explicitly. If we are given a lock service, then we expect the API to offer functions to acquire and release locks. The services we are talking about, however, do not expose a consensus API, so calling them “consensus services” is somewhat misleading.
If so, then why do people call them consensus services? Mainly because the services are often used for agreement on something: on a lock, on a master, on configuration. In the context of ZooKeeper, we have opted to call it a coordination kernel instead [3][4]. The rationale for the name was the following. The service itself exposes a file-system-like API so that clients can manipulate simple data files (znodes). The files can have some special properties like being ephemeral or sequential, but nonetheless they are small data files. We thought of terms like file systems, databases, key-value stores, but they did not feel entirely appropriate because of the following:
- It is not really a file system because it does not offer all the properties a typical file system does (e.g., partial reads and writes of files).
- It is not really a database because it does not really deal with bulk data and there are no sophisticated operators to manipulate the data.
- It is not really a key-value store because it does more than a typical key-value store offers (e.g., ordering, hierarchy).
- It is not really a lock service because the API does not expose locks directly.
Consequently, we decided to name it based on what it is used for rather than what it does, so coordination sounded appropriate. We also decided to call it a kernel because the API enables the implementation of primitives, like a distributed lock, but no primitive is directly exposed, like for example in the Chubby system [5]. The kernel exposes some small amount of functionality just enough to implement master election, locks, membership, etc.
The consensus problem, however, is really fundamental to understand how a system like ZooKeeper works and what it can offer. Part of the trouble with the name has to do with the fact that ZooKeeper is not a box to which you can simply ask “what have we agreed upon?”. It is more elaborate than that, and the goal of this post is to shed some light on how the consensus problem manifests in distributed systems and some caveats. As part of this exercise, we will be discussing how consensus manifests in the replication scheme of Apache Kafka and how it leverages ZooKeeper to simplify its operation. But first, some background on consensus.
A brief background on consensus
In the context of distributed systems design, consensus is often loosely used to mean some form of agreement. However, the distributed consensus problem is a well-defined problem. As described in the famous paper by Fischer, Lynch, and Paterson [2, 6], a consensus protocol is a system with n processes such that each process has an initial value and an output value that once set, cannot change anymore. Once a process sets its output value, we say that the process has decided, and once a process has decided, it can’t change its mind.
Isn’t this definition a bit narrow? Why can’t a process change its decision value? The kinds of problems that require consensus are things like transaction commit [2]. If a process commits its part and later decides to abort, then it can cause some trouble because the commit might have external effects (e.g., a customer has withdrawn US$1,000,000). Consequently, we assume that the decision value cannot be changed once set.
There are a few properties we expect from a solution to consensus:
- Agreement: We expect that all processes that do not crash agree on the same value
- Validity: The value has to be a value that one of the processes has proposed (otherwise we could simply decide to abort right up front and be done)
- Termination: We expect any execution of consensus to terminate. If the protocol never terminates, then the processes are vacuously agreeing on the same thing, which is not deciding. This termination property is actually what breaks consensus in asynchronous systems as the FLP impossibility result shows.
Such a consensus protocol is not exactly what we have in a system like ZooKeeper. It turns out that there is a much cooler problem that has been shown to be equivalent to consensus and that’s what ZooKeeper implements (actually a variant of that, see [7]). The problem is atomic broadcast [8].
Atomically broadcasting consists of making sure that processes deliver the same messages (agreement) and that they deliver them in the same order (total order). This property is really fundamental for replicated systems because if my messages are commands and I have an atomic broadcast implementation, then I can use it to broadcast commands to all replicas of a replicated system. All replicas are going to receive all commands in the same order, and each replica will execute the commands according to the order received. If the commands are deterministic, then the state across all replicas is guaranteed to be always consistent. This observation is the essence of replicated state machines [9].
ZooKeeper actually does not broadcast commands, it broadcasts state updates instead. Using state updates is a way of transforming the commands clients submit into idempotent transactions. For example, a znode can be updated conditionally, and upon updating the znode with a setData request, the version is automatically incremented. To transform this call into an idempotent transaction, we need to compute the new version and propagate the new state of the znode. Making a bit more concrete, here is a simplified version of the request and corresponding state update:
<setData, path, data, expected version> // setData request
<path, new data, new version> // corresponding txn
This is useful for reasons outside the scope of this discussion, but more detail is discussed in the Zab work [6].
On consensus and atomic broadcast, let’s walk through a simple argument to get an intuition for why they are equivalent. Using a consensus protocol implementation, processes can run a sequence of consensus instances to implement atomic broadcast. The input value of each consensus instance is a set of values to broadcast. Because the processes are running consensus, they deliver the same set of messages in each instance. The other direction is also simple. If we are given an atomic broadcast implementation, then to obtain a consensus implementation, each process simply proposes a value by broadcasting the value. The first message a process delivers contains the decision value, which is the same for all processes.
ZooKeeper and consensus
It makes a lot more sense to think of atomic broadcast when reasoning about ZooKeeper rather than consensus. But wait, aren’t they equivalent? Yes, they are, from a reduction point of view, but they still present different semantics. Here is a simple example of how the incorrect reasoning can lead to problems.
Say we have a system with three clients, one configurator (C) and two workers (W1 and W2). The configurator C tells the workers a flavor they are supposed to consume and it expects all workers to consume the same flavor. The flavor chosen by the coordinator can change over time and the coordinator communicates its choices to workers in a fault-tolerant manner via ZooKeeper. Now consider the following sequence of steps:
- C writes vanilla into ZooKeeper
- W1 reads vanilla
- C writes chocolate into ZooKeeper immediately after
- W2 reads chocolate and W1 is already consuming vanilla
It is obvious that the workers will be consuming different flavors because they read different values, but what exactly has gone wrong here? Isn’t the service supposed to give us consensus? It turns out that the kind of consensus that ZooKeeper offers is a uniform view of the updates to the ZooKeeper state. If two or more clients are able to observe all updates to the ZooKeeper service, then they observe the same updates applied in the same order, but not necessarily at the same time. Consequently, the kind of agreement it offers can’t be confused with always observing the same state. Being consistent does not mean that the values read are the same necessarily.
One way to get around this problem is to use this property about sequences of updates to get the workers to agree on the value, essentially implementing consensus using atomic broadcast like we discussed before. As soon as W1 reads a value, it can propose that they consume vanilla because the configurator has suggested so. W2 does the same, but because they have proposed different values, they need to break the tie. They can do it by picking the first value written using ZooKeeper sequential nodes.
Why does this proposal work compared to the original one? Because each of the workers has “proposed” a single value and no changes to those values are supposed to occur. Over time, as the configurator changes the value, they can agree on the different values by running independent instances of this simple agreement recipe.
Note that this scenario is simply to illustrate a problem when the reasoning around agreement and the service providing it is incorrect. The real solution to the problem will depend on the precise semantics of the application, and there are multiple ways of achieving that.
Consensus through a service
Consensus plays an important role in distributed systems and using a service like Apache ZooKeeper makes some aspects of replication simpler. To make the argument very concrete, we focus here on the replication scheme of Apache Kafka. Kafka uses Apache ZooKeeper for storing metadata. This metadata serves a number of purposes – persisting the set of brokers that form the replicas for a topic partition, electing a leader replica from amongst those for serving writes for its data and persisting the subset of nodes that are considered eligible to become the next leader, should the current leader of a partition fail.
The replication protocol of Kafka is explained in the documentation and this blog post, and here we cover just enough to make the argument understandable. Kafka exposes the abstraction of topics: clients produce and consume records via topics. Topics are further split into partitions for parallelism. The partition is the unit of parallelism and replication in Kafka. Amongst the set of replicas of a partition, there is one that is elected leader (using ZooKeeper) and the remainder are followers. The leader serves all reads and writes for a partition. Kafka also has the notion of in-sync replicas (ISR): the subset of the replicas that is currently alive and caught-up to the leader.
The ISR changes dynamically, and every time it changes, the new membership of the set is persisted to ZooKeeper. There are two important purposes that the ISR serves. First, all records written to a partition need to be acknowledged by this set before the leader declares them committed. Consequently, the ISR set must contain at least f + 1 replicas to be able to tolerate f crashes, and the value desired for f + 1 is set by configuration. Second, since the ISR has all the previously committed messages for a partition, to preserve consistency, the new leader must come from the latest ISR. Electing a leader from the latest ISR is important to guarantee that no committed message is lost during the leader transition. When a replica fails, it is removed from the ISR. When a replica comes back up after crashing, it is informed of the current leader and ISR (by reading from ZooKeeper) and it then synchronizes its data by pulling from the current leader until it is caught up enough to be made part of the ISR again. In this replication scheme, ZooKeeper is ultimately dealing with the metadata aspect of the replication (partition information and ISR membership), leaving it to the application (Kafka) to worry about replicating the actual data.
There is also an important difference between Kafka’s replication protocol and ZooKeeper’s replication protocol with respect to persistence. Because Kafka relies on ZooKeeper to be the “source of truth” for metadata, ZooKeeper must provide strong persistence guarantees. As such, it does not acknowledge a write request until it has synced data to the disks of a quorum of ZooKeeper servers. Because of the volume of data that Kafka brokers need to handle, they cannot afford to do the same and they do not sync partition data to disk. Messages of a partition are written to the corresponding file, but there is no call to fsync/fdatasync, which means that the data stays in the operating system page cache after the write, and is not necessarily flushed to disk media. This design choice has a huge positive impact on performance, but has the side effect that a recovering replica might not have some messages that it previously acknowledged.
Why ISRs and not quorums
A great advantage of using quorums in replicated systems is to be able to mask crashes. Votes from any large enough subset of replicas (e.g., a majority) are sufficient to commit. In a quorum-based system that is replicated 2f + 1 ways, if any f replicas crash, then the system can still make progress transparently (with possibly some small hiccups). Every write operation goes to all replicas, but only responses from a majority quorum are necessary to commit the write. Check the illustration below:
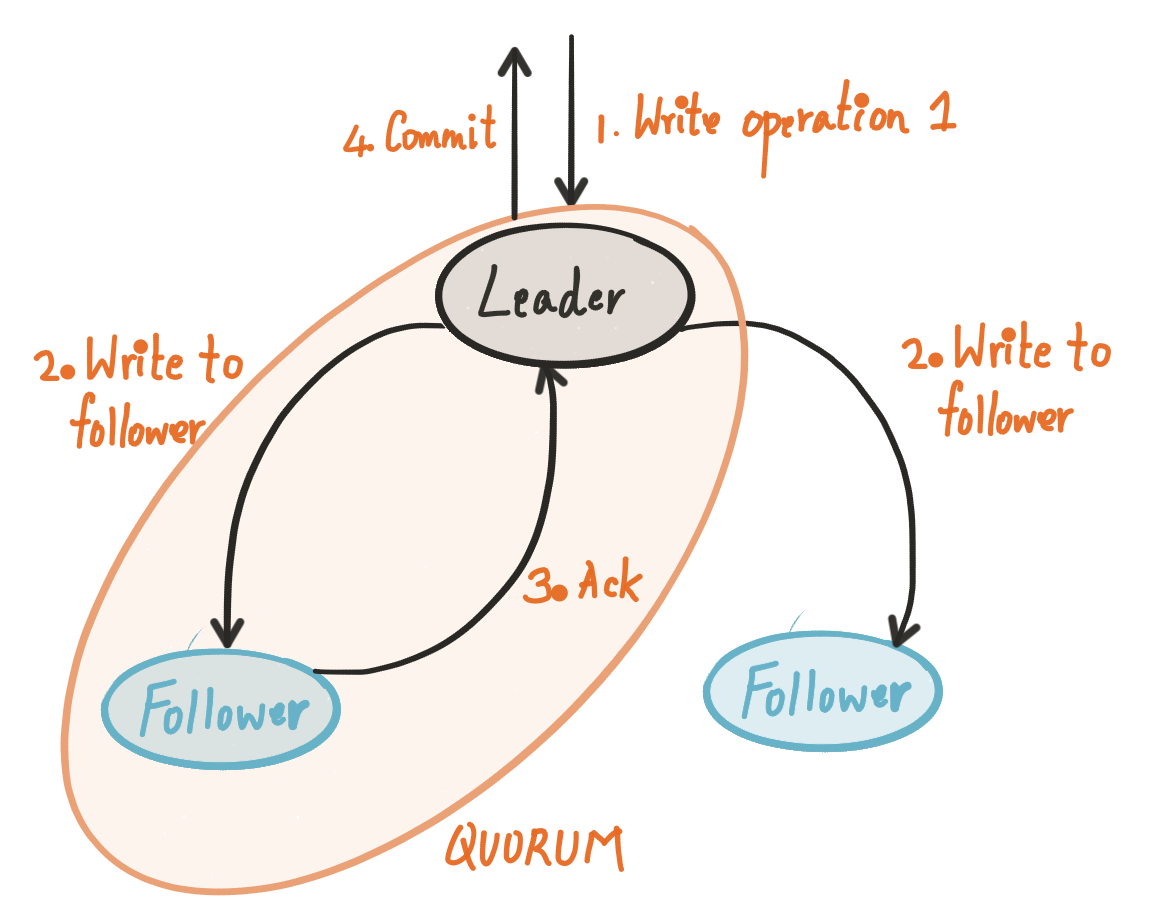
An important disadvantage of majority quorums is their requirement of at least (n + 1)/2 acknowledgments, so it grows with the number of replicas n. This quorum system scheme works well with systems like ZooKeeper because it deals with metadata: volume is small and writes are infrequent, typically not in the critical path of common operations.
The ISR scheme of Kafka does not use quorums in the sense described above and requires all the members of the current ISR to respond:
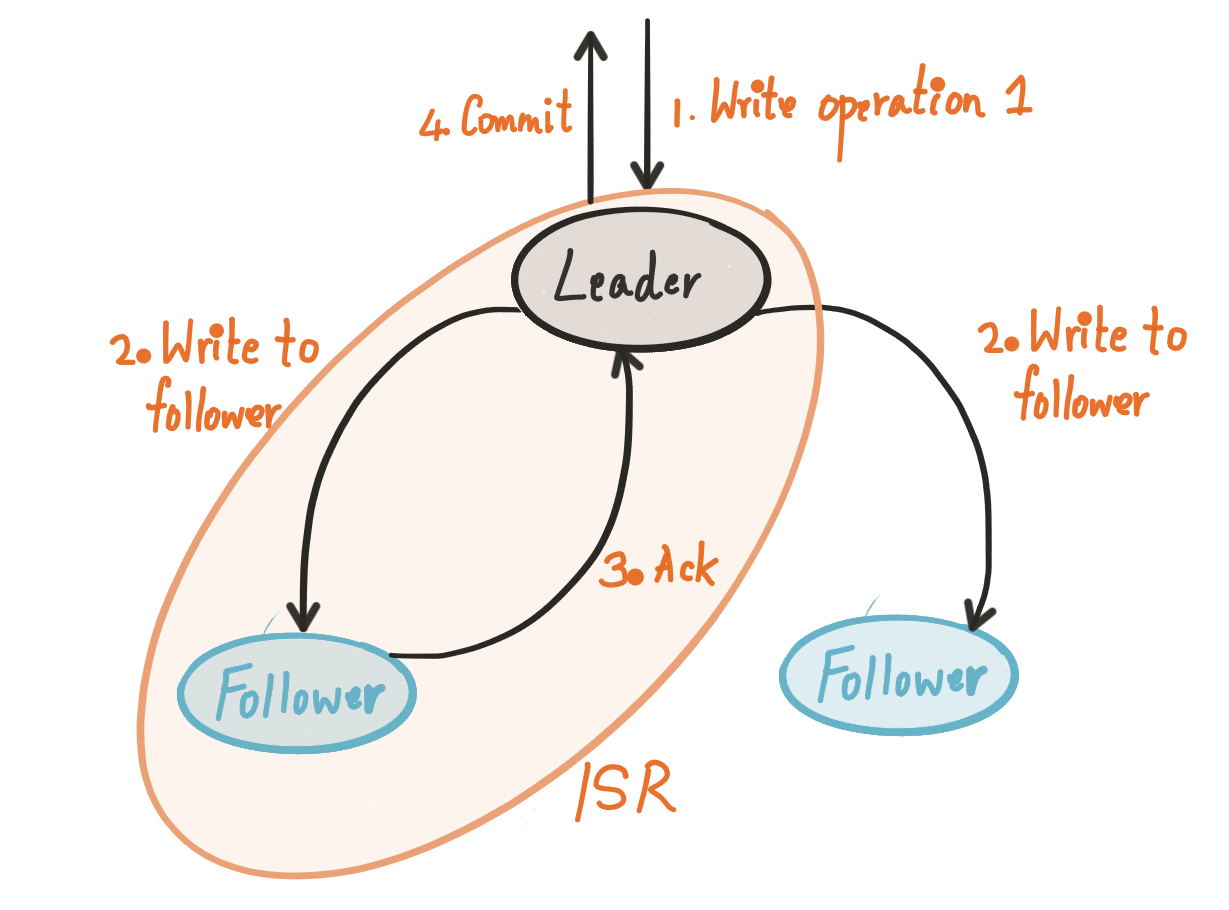
For a write to be committed, all replicas in the ISR have to respond with an acknowledgement, not just any majority. Different from classic quorum systems, the size of the ISR is decoupled from the size of the replica set, which gives more flexibility into the configuration of the replica set. For example, we can have 11 replicas with a minimum ISR size of 3 (f = 2). With majority quorums, having 11 replicas implies quorums of size 6 necessarily.
Keep in mind that the size of the minimum ISR is directly related to the persistence guarantee the system offers. Since the constraint on the minimum size of the ISR can be tuned via configuration, the durability guarantee is similar to the one ZooKeeper provides in the sense that writes are not taken if the number of failed replicas falls below the expected quorum size. It essentially trades off availability for durability where new writes are not accepted if the system cannot guarantee that they can be committed. Kafka’s replication scheme is flexible in this respect. By letting the minimum size of the ISR be configurable, it allows topics to trade off availability for durability, and the other way around, without the requirement that quorums contain a majority of replicas.
Though the ISR scheme is more scalable and tolerates more failures, it is also more sensitive to the performance of a certain subset (ISR) of the replicas. When a majority quorum based scheme would’ve merely ignored the slowest replica, this scheme will pause all writes to the partition until the slowest replica is removed from the ISR, if it was part of it. In most failure modes, replicas are removed quickly. For soft failures, unresponsive replicas are removed after a certain timeout. Similarly, slow replicas are removed if they fall sufficiently behind the leader, as defined by a configuration.
For data systems like Apache Kafka, this flexibility in its replication scheme has the advantage of providing a more fine-grained control over the persistence guarantee, which has proven to be great when storing large volumes of data in production. As another data point, systems like Apache BookKeeper have also used similar schemes in which the number of replicas and acknowledgements are independent. BookKeeper, however, does not fix an ISR like Kafka.
It is interesting to point out that this scheme is close to the one described in the PacificA work [10]. In the PacificA work, the framework separates the configuration management of replica groups from the actual data replication, just like Kafka. It also shares some properties with Cheap Paxos [11]. With Cheap Paxos copies of the data are sent to only f + 1 replicas while in Kafka it is sent to all replicas (to keep the replicas warm, not for correctness). Both protocols, however, propose to keep a fixed subset of f + 1 replicas up to date, and reconfigure the set upon a suspicion of crash. Cheap Paxos performs reconfiguration from within the protocol, whereas Kafka relies on an external replicated state machine (ZooKeeper).
Where is consensus in all this?
In the Kafka replication protocol, consensus is disguised in the ISR update protocol. Because ZooKeeper ultimately exposes an atomic broadcast primitive, by storing the ISR information in ZooKeeper, one is essentially guaranteed agreement on the succession of ISR changes. When a replica recovers after a crash, it can go to ZooKeeper and find what the latest partition metadata (leader, ISR) is and synchronize accordingly to obtain the latest committed messages. Because all replicas agree (via ZooKeeper) on what the latest ISR is, there is no possibility of split brain scenarios.
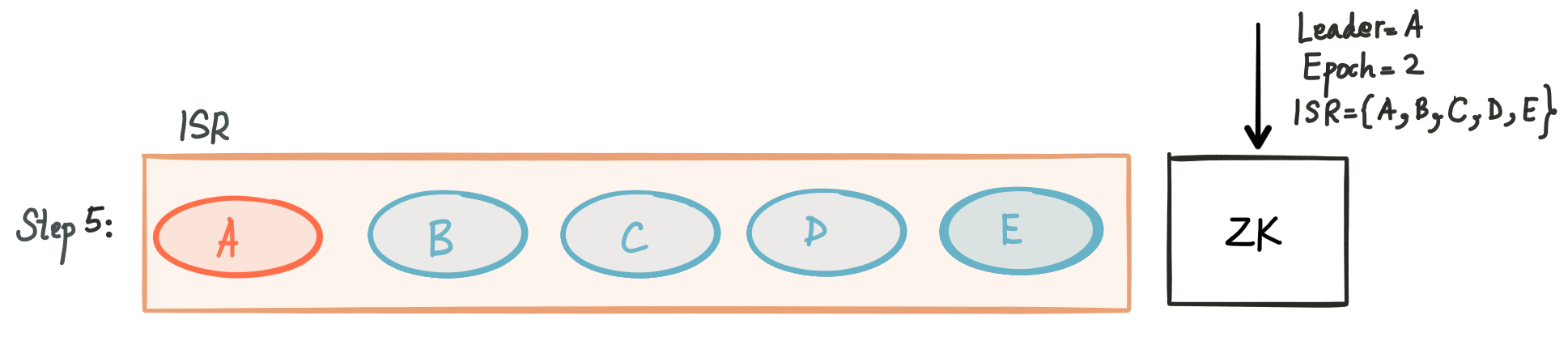
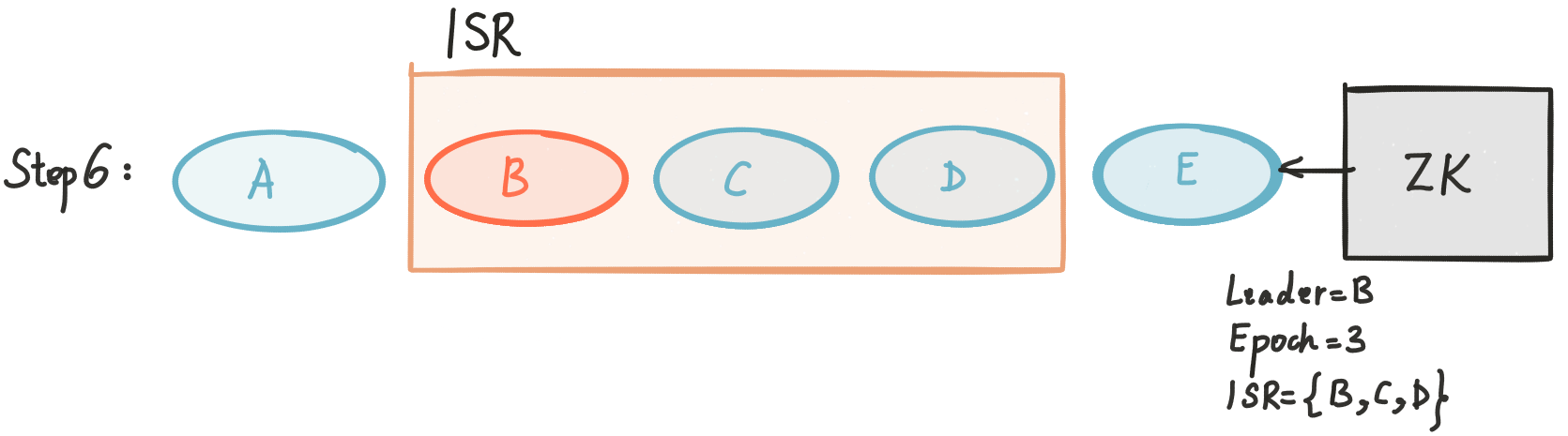
Let’s go over a couple of scenarios to get better insight on how this works. Say we have 5 replicas for a partition {A, B, C, D, E}, and the ISR set contains initially all replicas. The following figure illustrates this scenario:
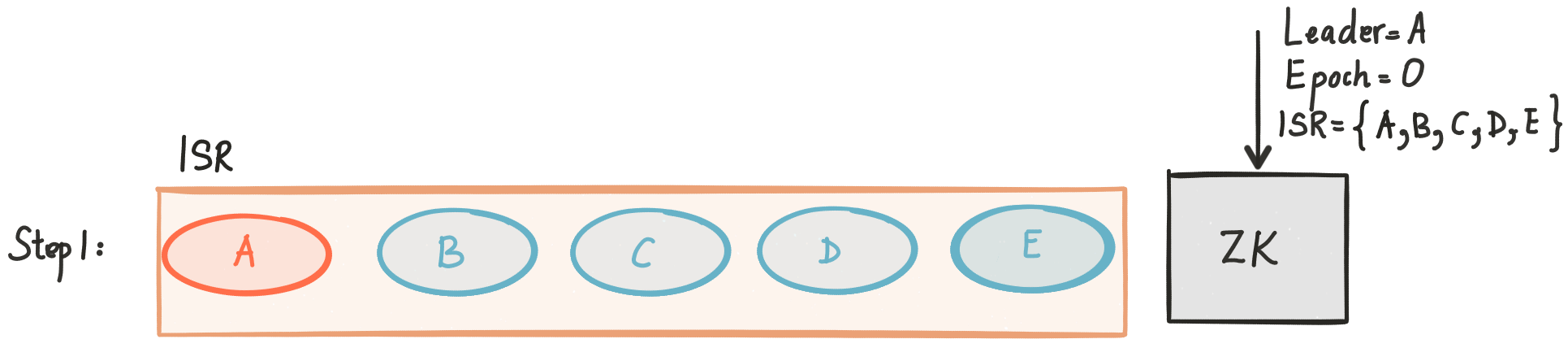
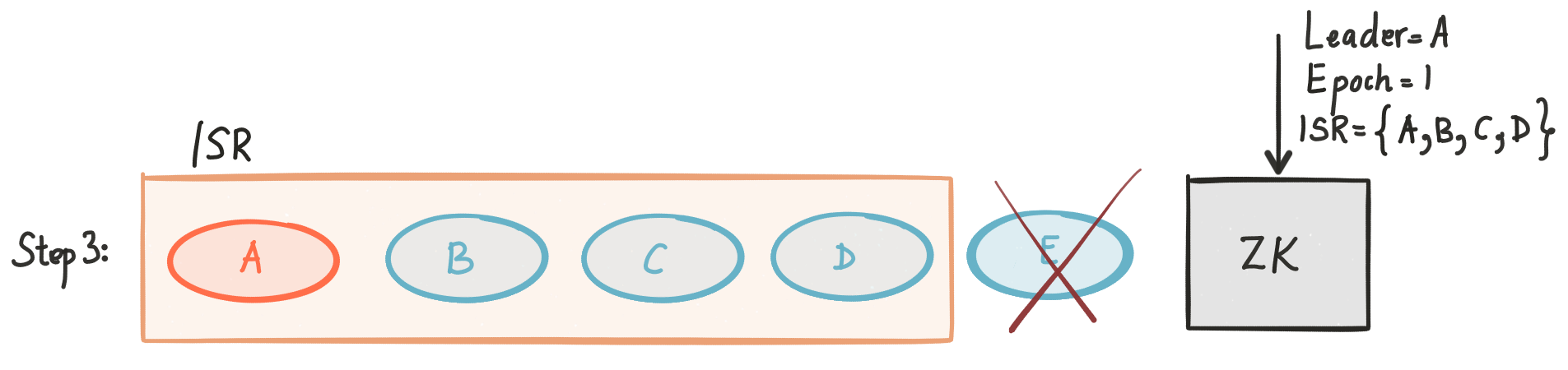
At some point replica E crashes.
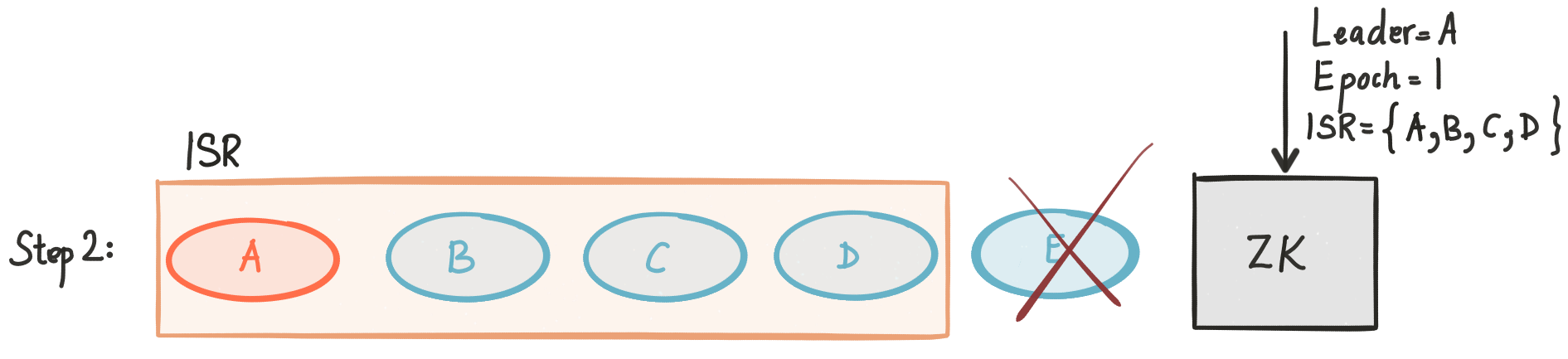
Once it starts the recovery process, it reads the state of the partition from ZooKeeper and learns that A is the leader for the current ISR.

Once it is done syncing up, it is added back to the ISR.
If ZooKeeper were not present, then replica E would need to talk to the other replicas to figure out which one is leading to sync up. Not being able to query a “source of truth” like ZooKeeper opens up to all sort of complications because replicas can be crashed or partition away, and this is a key reason for quorum protocols in the absence of dependency like ZooKeeper.
Even with ZooKeeper, there could be race conditions that we need to be aware of. Let’s look at a different, slightly more elaborate example. Say that after getting the state of partition in Step 3 replica A crashes.
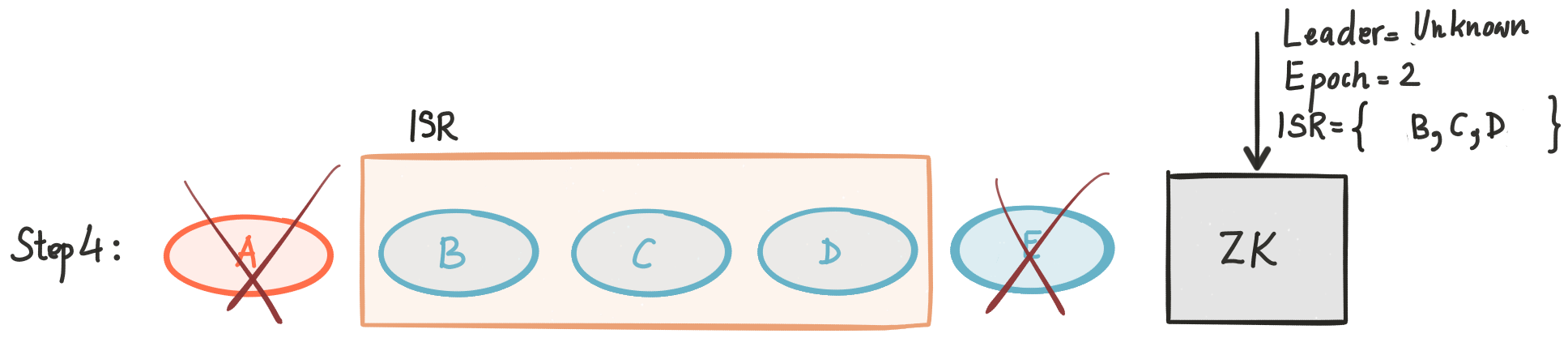
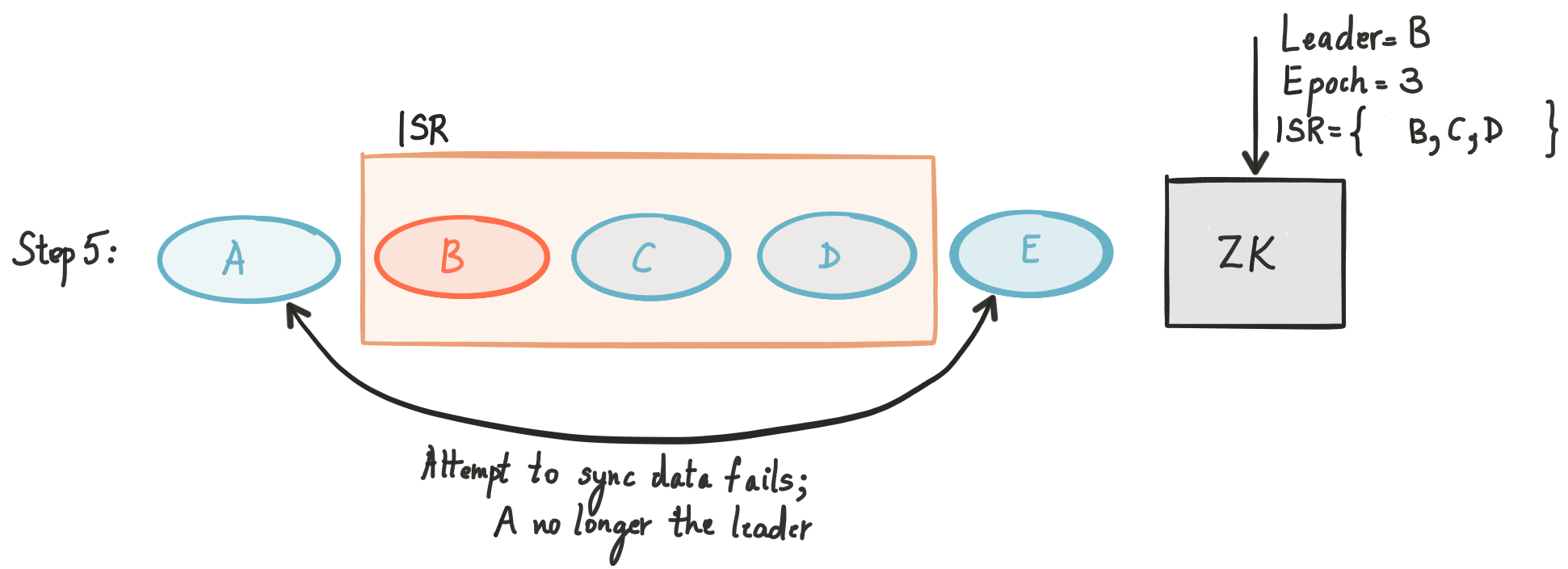
When E comes back and tries to get state out of A, A tells E that it is not the leader any longer. Replica A in this case goes back to ZooKeeper and reads the state until it gets a more recent value (it can use notifications to be more efficient).
Silent data loss
Another advantage of relying on ZooKeeper is to be able to handle faulty disks. In the 5-replica scenario of the previous section, replica E could have lost its disk state completely and yet it recovers correctly. Replica E is able to recover correctly because it knows the composition of the ISR set before it crashed, so it make decisions about where to pull the state from appropriately. According to this post, the main difficulty with faulty disks is the fact that when a faulty replica recovers, it does not know if it is just starting from scratch or if its persistent state is gone. The use of the oracle enables replicas to make such a distinction. If a Kafka node crashes and loses the data it had on disk (or that node is moved to another physical machine), then when it restarts it will correctly restore its state from other Kafka replicas.
The bottom line
Using a system that solves distributed consensus at its core by implementing a broadcast protocol and exposing the functionality via a simple API has been a successful approach for the design of many distributed systems currently used in production. We have discussed here one use case, which is Apache Kafka that uses Apache ZooKeeper for the coordination and metadata management of topics. Kafka provides the abstraction of replicated logs, and the use of ZooKeeper made possible a more flexible replication scheme.
Interestingly, other systems have opted for replicating logs directly on a replicated state machine implementation using Paxos [12]. This is, in fact, an example of a scenario in which ZooKeeper is clearly not a good choice. Storing logs directly implies a large volume of writes and a large amount of data (ZooKeeper servers store data in memory and the service uses quorum replication for writes), so it made sense to develop systems like Kafka and BookKeeper for log replication on top of ZooKeeper. Both styles of design have worked well in practice, but we are clearly biased towards the use of a system like ZooKeeper because it enables both the design and implementation of more flexible schemes (e.g., for replication) by exposing agreement through a file-system like API, and a clear separation between data and metadata.
Acknowledgements
We would like to thank our colleagues for feedback on a draft version of this post: Ewen Cheslack-Postava, Jason Gustafson, Jay Kreps, Michael Noll, Ben Stopford, and Guozhang Wang.
References
[1] Diego Ongaro and John Ousterhout, “In Search of an Understandable Consensus Algorithm”, Proceedings of the USENIX Annual Technical Conference, 2014, pp. 305-319.
[2] Michael Fischer, Nancy Lynch, and Michael Paterson, “Impossibility of Distributed Consensus with One Faulty Process”, Journal of the ACM, Vol. 32, No. 2, April 1985, pp. 374-382.
[3] Patrick Hunt, Mahadev Konar, Flavio Junqueira, Ben Reed, “ZooKeeper: Wait-free coordination for Internet-scale systems”, Proceedings of the USENIX Annual Technical Conference, 2010, pp. 145-158.
[4] Flavio Junqueira, Ben Reed, “ZooKeeper: Distributed Process Coordination”, O’Reilly, 2013.
[5] Mike Burrows, “The Chubby lock service for loosely-coupled distributed systems”, Proceedings of the 7th Symposium on Operating systems design and implementation (OSDI), 2006, pp. 335-350.
[6]Jim Gray and Leslie Lamport, “Consensus on Transaction Commit”, ACM Transactions on Database Systems (TODS), Volume 31 Issue 1, March 2006, pp. 133-160
[7] Flavio Junqueira, Benjamin Reed, and Marco Serafini, “Zab: High-performance broadcast for primary-backup systems”, Proceedings of the IEEE/IFIP International Conference on Dependable Systems & Networks (DSN), 2006, pp. 245-256.
[8] Tushar Chandra and Sam Toueg, “Unreliable failure detectors for reliable distributed systems”, Journal of the ACM, Volume 43 Issue 2, March 1996, pp. 225-267.
[9] Fred Schneider, “The state machine approach: A tutorial”, Fault-Tolerant Distributed Computing, Lecture Notes in Computer Science Volume 448, 1990, pp. 18-41.
[10] Wei Lin, Mao Yang, Lintao Zhang, Lidong Zhou, “PacificA: Replication in Log-Based Distributed Storage Systems”, Microsoft Research, MSR-TR-2008-25, Feb. 2008.
[11] Leslie Lamport and Mike Massa, “Cheap Paxos“, Proceedings of the IEEE/IFIP International Conference on Dependable Systems and Networks (DSN), 2004, pp. 307-314.
[12] Jason Baker, Chris Bond, James C. Corbett, JJ Furman, Andrey Khorlin, James Larson, Jean-Michel Leon, Yawei Li, Alexander Lloyd, Vadim Yushprakh, “Megastore: Providing Scalable, Highly Available Storage for Interactive Services”, Proceedings of the Conference on Innovative Data system Research (CIDR), pp. 223-234, 2011.

Avez-vous aimé cet article de blog ? Partagez-le !
Abonnez-vous au blog Confluent



From Dumb Pipes to a Smart Data Plane: Introducing Schema IDs in Apache Kafka® Headers
Confluent’s Schema IDs in headers transform Kafka from "dumb pipes" to a "smart data plane." By moving metadata out of payloads, teams can schematize topics without breaking legacy apps or requiring big-bang migrations. This unlocks governed, AI-ready data for Flink and lakehouses with ease.


Queues for Apache Kafka® Is Here: Your Guide to Getting Started in Confluent
Confluent announces the General Availability of Queues for Kafka on Confluent Cloud and Confluent Platform with Apache Kafka 4.2. This production-ready feature brings native queue semantics to Kafka through KIP-932, enabling organizations to consolidate streaming and queuing infrastructure while...