[Virtual Event] Agentic AI Streamposium: Learn to Build Real-Time AI Agents & Apps | Register
Event Streams Are Nothing Without Action
The transition from a passive event stream to an active component like a workflow engine is very interesting. It raises a lot of questions about idempotency, scalability, and the capability to replay streams with changed logic. This blog post walks you through a concrete, real-life example of a vehicle maintenance use case, where billions of sensor data points are sent via Apache Kafka® that must be transformed into insights in order for mechanics to take action. For this project, the team developed a stateful connector that starts a new process instance for a mechanic only once for every new insight, but it can also inform that process instance if the problem no longer exists.
Streaming vehicle data for actionable insights
A customer with a large vehicle fleet needed to solve the following challenge: all vehicles in their fleet constantly sent sensor data in a steady stream of events. They had several stream processors in place to generate insights on the sensor data but needed a better way to gain more meaningful and actionable insights. For example, one sensor delivers an oil pressure measurement of 80 PSI. Now, this is not great information, as you have to know if 80 PSI is good or bad, which might even depend on other factors like vehicle type, speed, or air temperature.
That’s why there is a stream processor in place that acts on the measurement and generates a new event stream containing insights, such as the oil pressure being critically high.
Generated insights often lead to required actions in the workflow engine, typically to schedule maintenance or possibly to start an emergency maintenance procedure. This is a pretty common pattern with event streaming: You get a huge amount of raw data, generate insights from it, and then you have to act. This pattern is also described in the article If an Event Is Published to a Topic and No One Is Around to Consume It, Does It Make a Sound?

Source: If an Event Is Published to a Topic and No One Is Around To Consume It, Does It Make a Sound?
The real action for vehicle maintenance is controlled by an executable process model expressed in the Business Process Model and Notation (BPMN) language, which can be directly executed on the workflow engine Camunda. A simplified version of the process model might look like this:
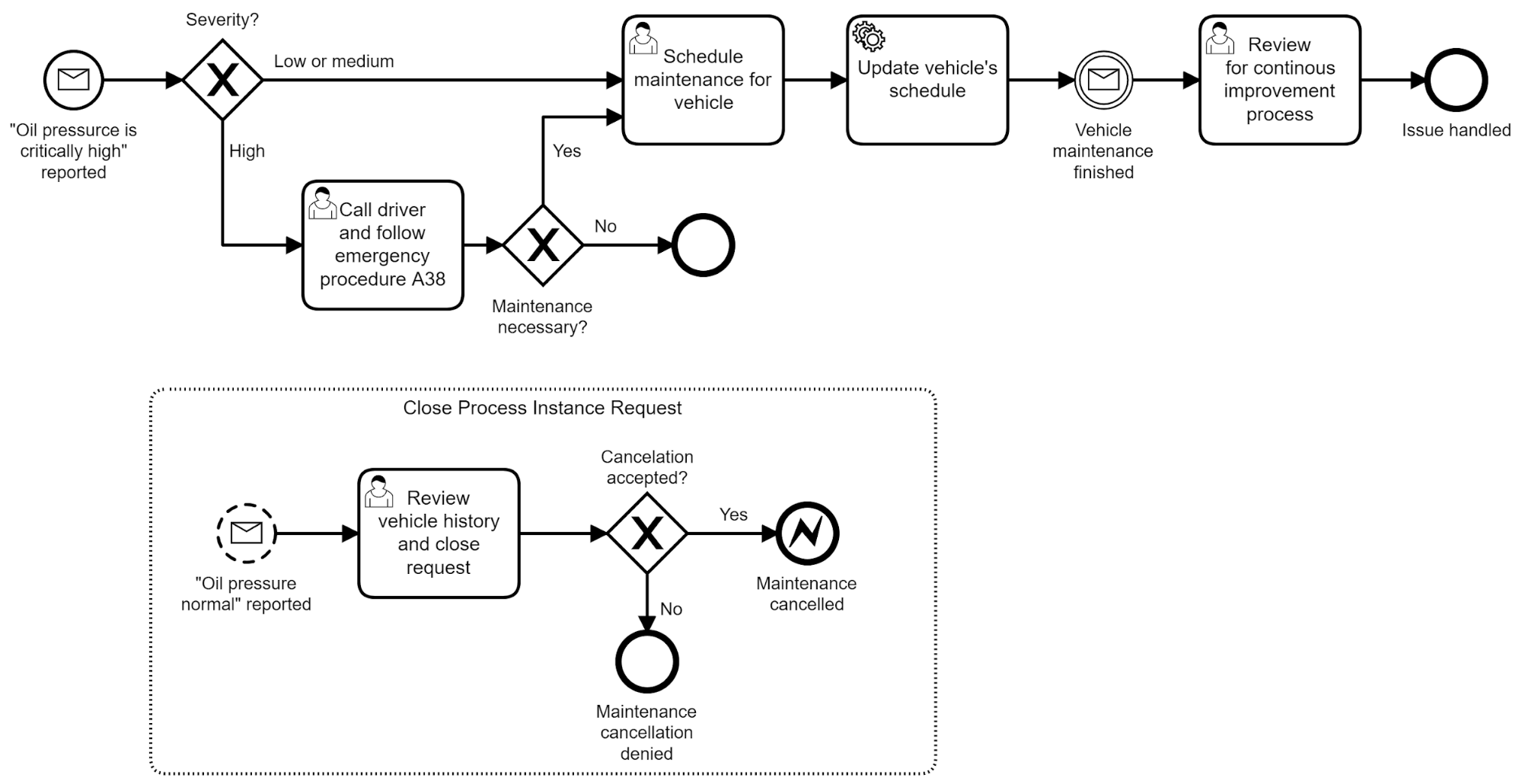
Source: If an Event Is Published to a Topic and No One Is Around To Consume It, Does It Make a Sound?
Logically, this process model is connected to the event streams by the so-called message events in BPMN, as pictured by the circles with the envelope symbol. Every such element can react to triggers outside of the workflow engine, such as entries in a Kafka stream.
In this example, a new process instance is started once there is an “oil pressure critically high” event. A running process instance can also be influenced by other events. For example, this process would be canceled (after a review from a mechanic) whenever the oil pressure returns to normal.
Preparing data streams to trigger meaningful actions
The translation between the stream and the process is a bit more complicated than just routing all events from the insight event stream to the workflow engine because you need to solve a couple of challenges, especially duplicate events, time windowing, and semantic aggregation of multiple insights. Let’s explore this a bit further.
Preventing duplicate events
In distributed systems, it might easily happen that you receive the same event twice, hence you need the capability to de-duplicate messages. This can be done by checking the technical event ID generated by the sensor producing the data.
Kafka, for example, guarantees this on the broker level, and Camunda’s workflow engine can also make sure a message is only processed once.

Source: If an Event Is Published to a Topic and No One Is Around To Consume It, Does It Make a Sound?
Analyzing streams with time windowing
Assume that you get high-oil-pressure events continuously for a few minutes but not as technical duplicates. This indicates that the problem is continuous. After a certain amount of time, this could lead to a new insight that the oil pressure is now critically high for too long. Short periods of high oil pressure might simply be ignored, but this new event is critical.
In Kafka, you can solve this by time windowing and using ksqlDB or Kafka Streams to produce a new stream of data.

Source: If an Event Is Published to a Topic and No One Is Around To Consume It, Does It Make a Sound?
Semantic aggregation
The biggest challenge in the vehicle maintenance project was semantic aggregation. This involved the following cases:
- The first occurrence of a certain event leads to the start of a process instance, but further occurrences of the same event type (for the same vehicle) are ignored if a process instance is already running. If not, a new instance is started.
- Some events are routed toward an existing process instance with a defined semantic, for example, to cancel the process instance. These events are ignored if no process instance is running.

Source: If an Event Is Published to a Topic and No One Is Around To Consume It, Does It Make a Sound?
This semantic aggregation was solved by a custom connector that also provided the overall connection of the streams to the workflow engine.
Connecting the stream with the workflow engine
The custom connector listens to the Kafka stream and executes the right actions in the workflow engine, which is illustrated in the figure below. At the same time, it keeps a persistent history of actions to allow for semantic aggregation. The combination of de-duplication and semantic aggregation using persistence also allows for the replay of streams, which is used to tune and enhance the stream processors to find insights.
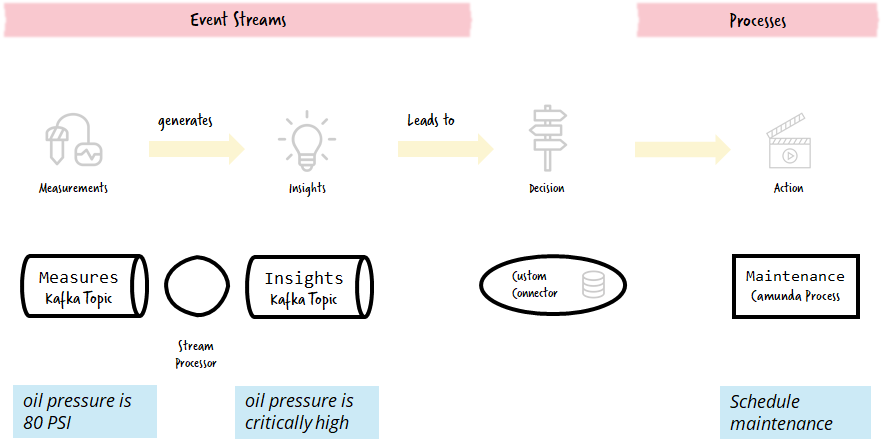
Source: If an Event Is Published to a Topic and No One Is Around To Consume It, Does It Make a Sound?
In the vehicle maintenance use case, the connector used Java and the Java clients of Kafka and Camunda. This resulted in an easy-to-operate component that has already served billions of sensor data points. Unfortunately, the source code is not open source, but always feel free to reach out to discuss your use case.
Conclusion
If you want to get started with Kafka and Camunda, the Camunda connectors and their examples are a good starting point. Note that this connector cannot handle all the requirements described above out of the box, so you will need to write custom software.
If you want to learn more about streaming and process automation, take a look at the Kafka Summit version of this blog post or the Practical Process Automation book.
Avez-vous aimé cet article de blog ? Partagez-le !
Abonnez-vous au blog Confluent



How to Implement Your First ML Function in Streaming
Learn how to add your first ML model to a real-time streaming pipeline. Learn a simple, low-risk pattern for inference, scoring, and deployment with Apache Kafka®.



Sustainable Streaming Architectures: A GreenOps Guide to Efficient, Low-Carbon Data Systems
Design energy-efficient, low-cost streaming systems. Learn GreenOps patterns to reduce compute waste, optimize storage, and lower the carbon footprint of real-time data.