[Virtual Event] Agentic AI Streamposium: Learn to Build Real-Time AI Agents & Apps | Register
Creating a Data Pipeline with the Kafka Connect API – from Architecture to Operations
Pandora began adoption of Apache Kafka® in 2016 to orient its infrastructure around real-time stream processing analytics. As a data-driven company, we have a several thousand node Hadoop clusters with hundreds of Hive tables critical to Pandora’s operational and reporting success. The Kafka Connect API, a framework for building and running reusable connectors between Kafka and other systems, is designed to support efficient real-time copying of data. It fits our requirements of being able to connect applications with high volume output to our Hadoop cluster to support our archiving and reporting needs.
Pandora’s ad trafficking infrastructure was the first use case for Kafka and the Kafka Connect API in production. Our ad serving infrastructure determines which ad to serve at what time, and it tracks events like impressions, clicks and engagements. There are billions of tracking events per day and since these events are the source of truth for advertising and billing, it is critical that they are reliably stored in HDFS for posterity.
In order to achieve real-time benefits, we are migrating from the legacy batch processing event ingestion pipeline to a system designed around Kafka. Our new architecture was designed to support reliable delivery of high-volume event streams into HDFS in addition to providing the foundation for real-time event processing applications such as anomaly detection, alerting and so on. Kafka not only provides an opportunity for streamlined event processing, but it also gives us the security controls needed to ensure that our pipeline can only be interacted with by authorized clients.
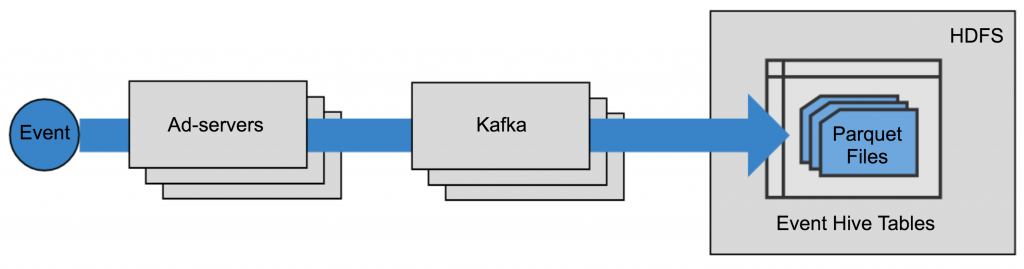
In this blog post, we will talk about how we designed and operationalized the data pipeline from our ad serving infrastructure to HDFS using Kafka and the Confluent certified HDFS connector, as well as Schema Registry. We will talk through the end-to-end production pipeline in detail and share how we configure, monitor and operate the Kafka HDFS connector.
Design the Data Pipeline with Kafka + the Kafka Connect API + Schema Registry
Our ad server publishes billions of messages per day to Kafka. We soon realized that writing a proprietary Kafka consumer able to handle that amount of data with the desired offset management logic would be non-trivial, especially when requiring exactly-once-delivery semantics. We found that the Kafka Connect API paired with the HDFS connector developed by Confluent would be perfect for our use case.
We’ve also found it painful not having a central authority on data structures that can share their respective schemas across all services and applications. Without a central registry for message schemas, data serialization and deserialization for a variety of applications are troublesome and the pipeline is fragile when schema evolution happens. We found Confluent Schema Registry is a great solution for this problem.
To address the above two problems, we integrated the Kafka Connect API and Schema Registry into our Kafka-centered data pipeline.
As shown below, the entire Adserver event ingestion pipeline consists of Adserver Kafka Producer, Schema Registry, Kafka Cluster, Kafka Connect Cluster and HDFS.
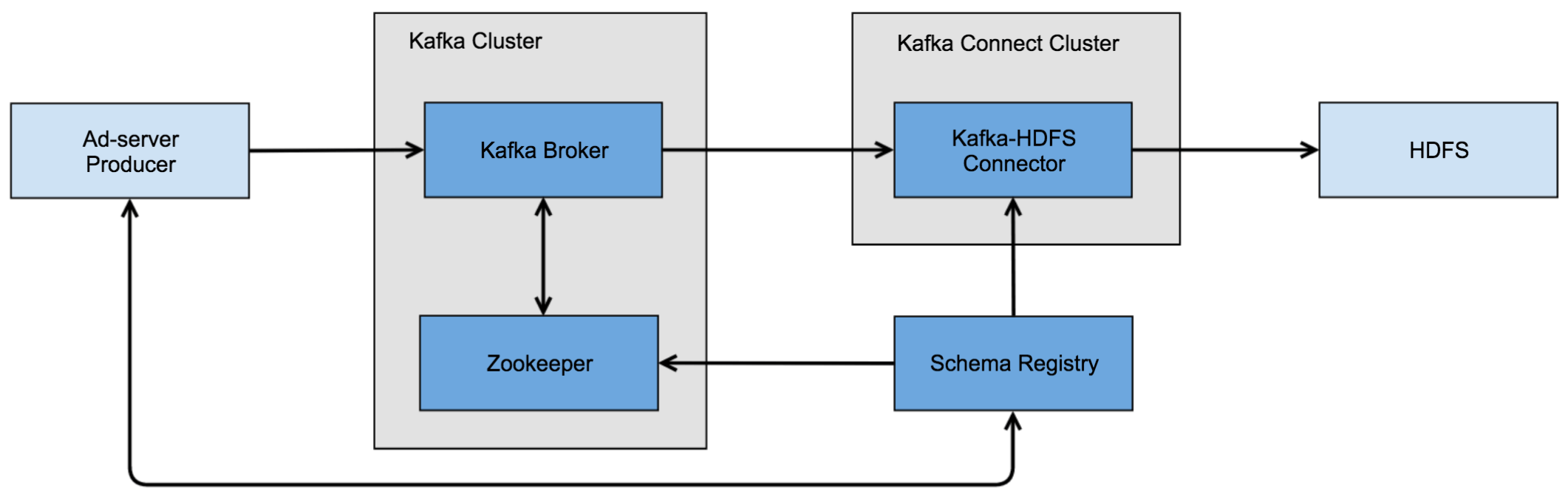
Put the Real-time Pipeline in Production
The detailed workflow in production contains three steps: create and register schema, produce Kafka messages and consume Kafka messages using HDFS connector.
Step 1: Create and Register Schema
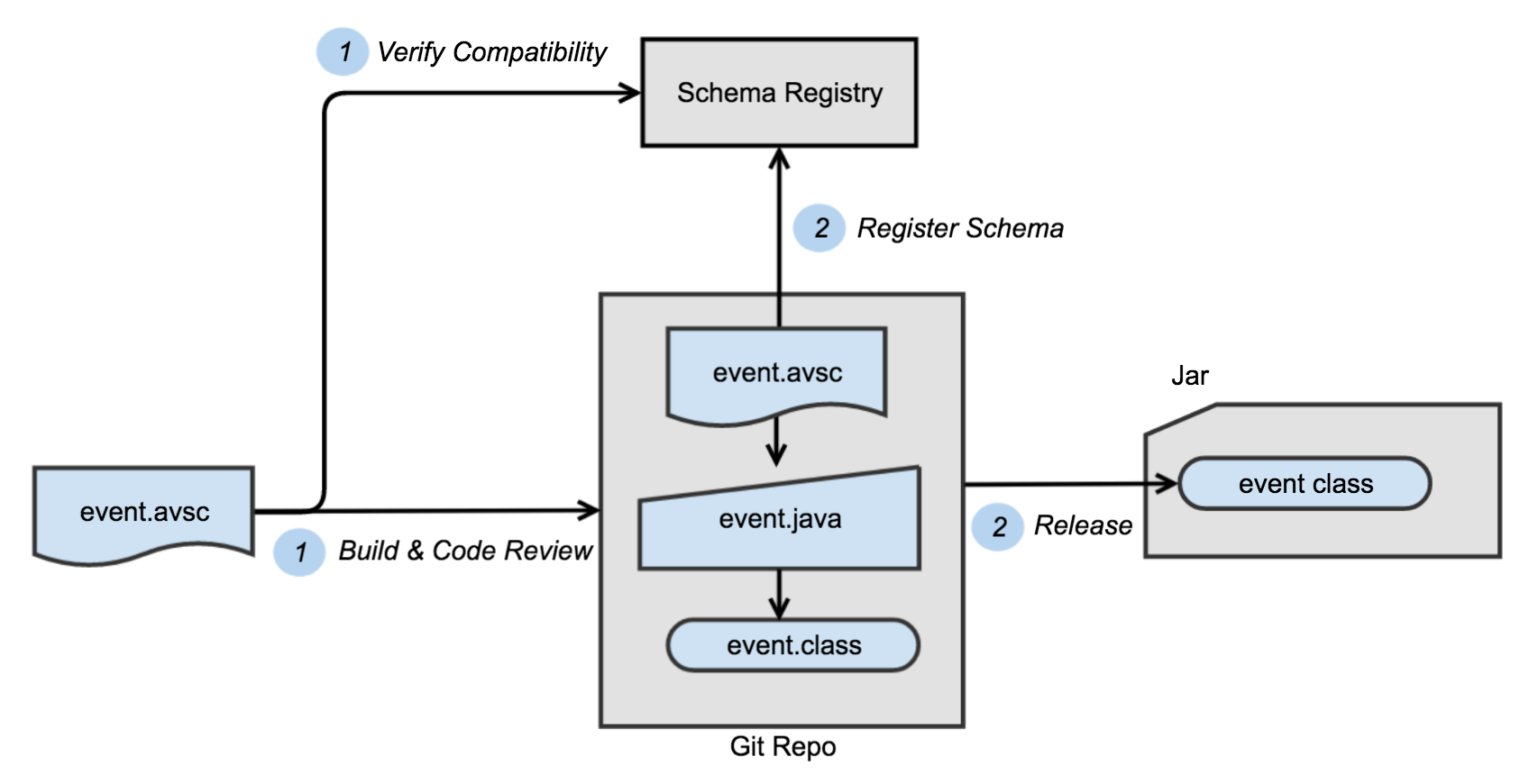
We created a proprietary Gradle plugin to assist developers in managing message formats and compatibility. Developers create or edit .avsc files locally like the one below, and Gradle will check the schema compatibility against Schema Registry using its REST interface, and if the schema is compatible, generate Java classes of the corresponding event schema with avro-tools. Next, the developer will be able to create a pull request for the new schema, and once the code change is approved and merged, our build tool will use Gradle to conduct one more compatibility check against Schema Registry, and then actually update the schema in Schema Registry, and release a respective Jar to our local Maven repository.
Step 2: Produce Kafka Messages
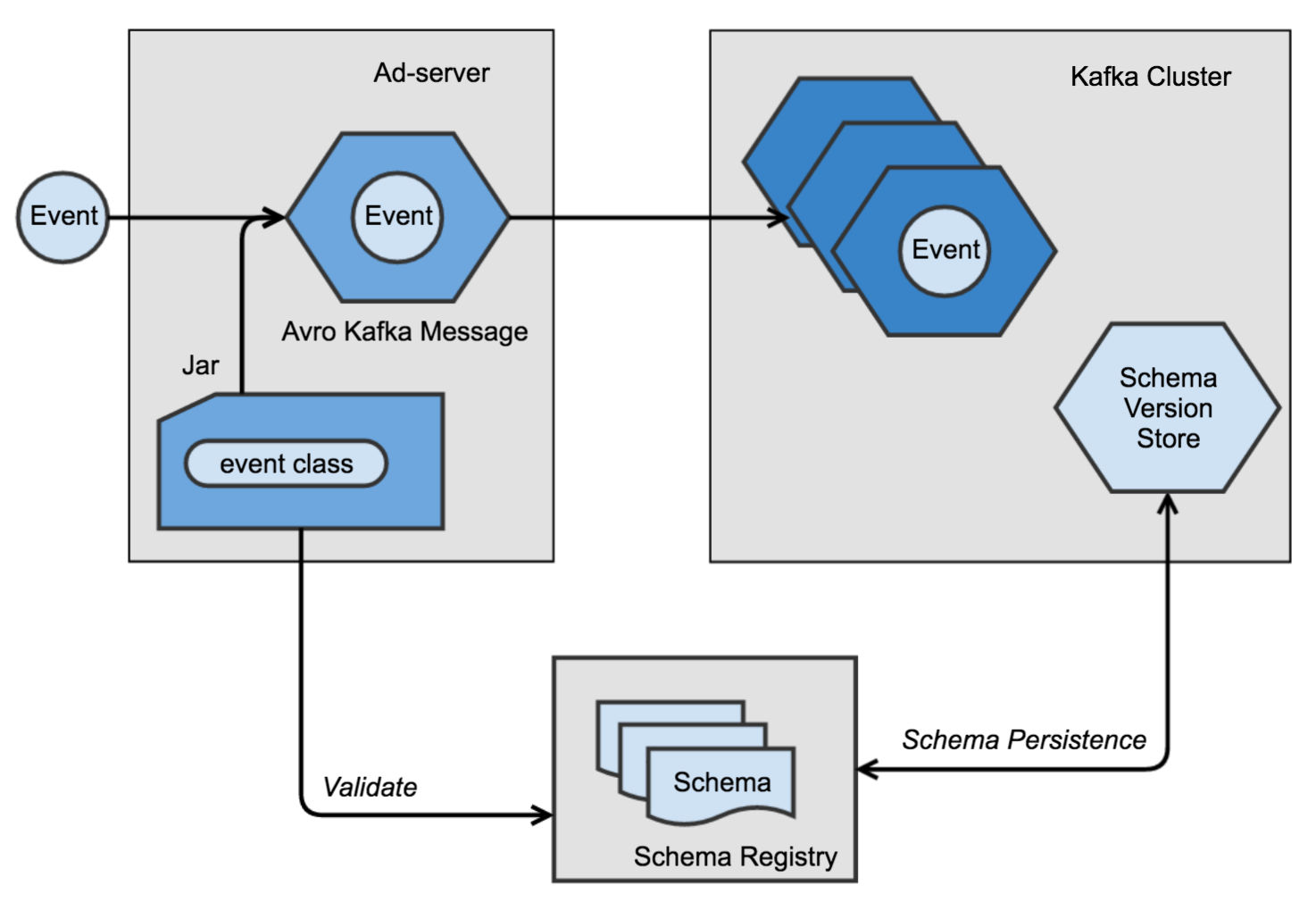
The ad server uses the event classes and Schema Registry to validate data before it’s written to the pipeline – ensuring data integrity – and then generates Avro-serialized Kafka messages with the validated schema.
Step 3: Consume Kafka Messages using HDFS Connector
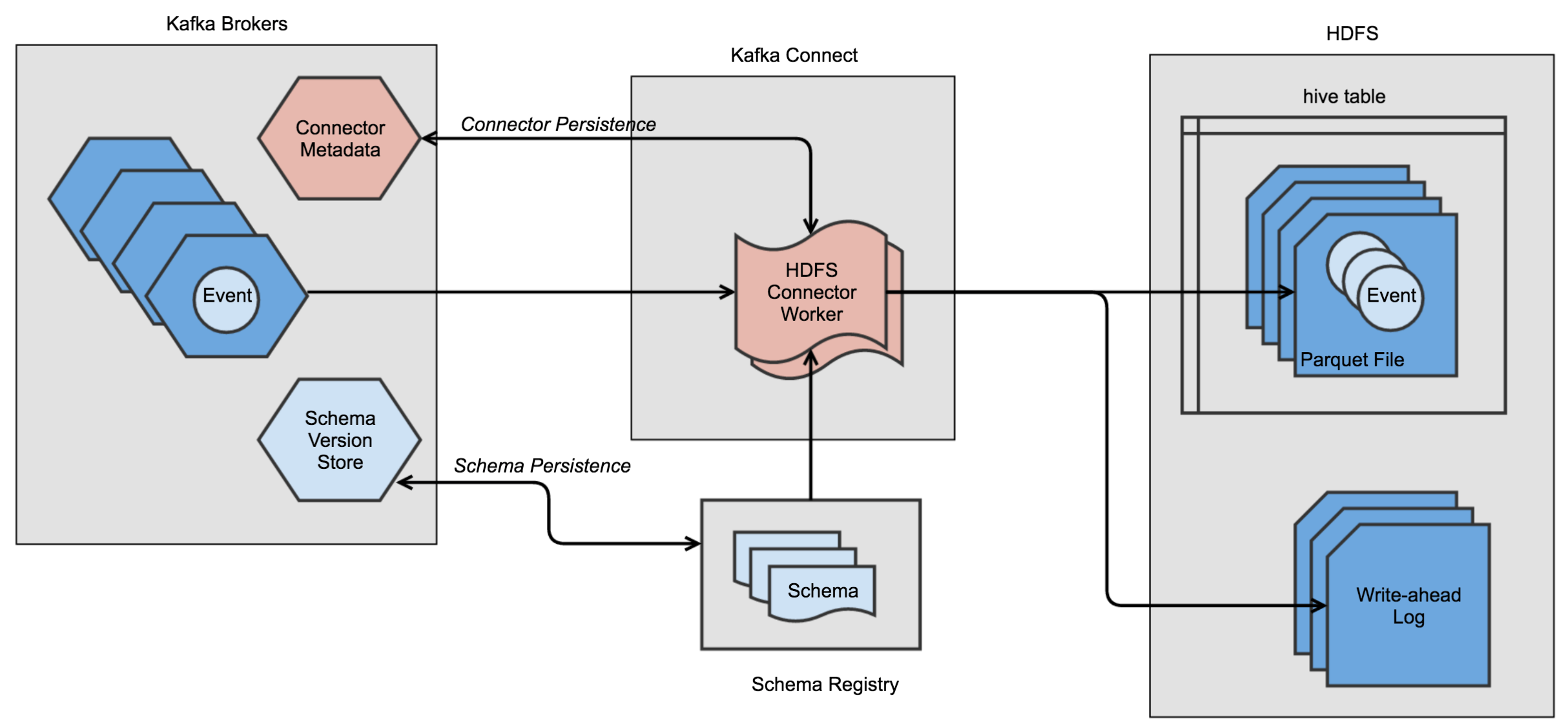
As a consumer, the HDFS Sink Connector polls event messages from Kafka, converts them into the Kafka Connect API’s internal data format with the help of Avro converter and Schema Registry, and then writes Parquet files into HDFS. The connector also writes a write-ahead log to a user defined HDFS path to guarantee exactly-once delivery.
High Availability
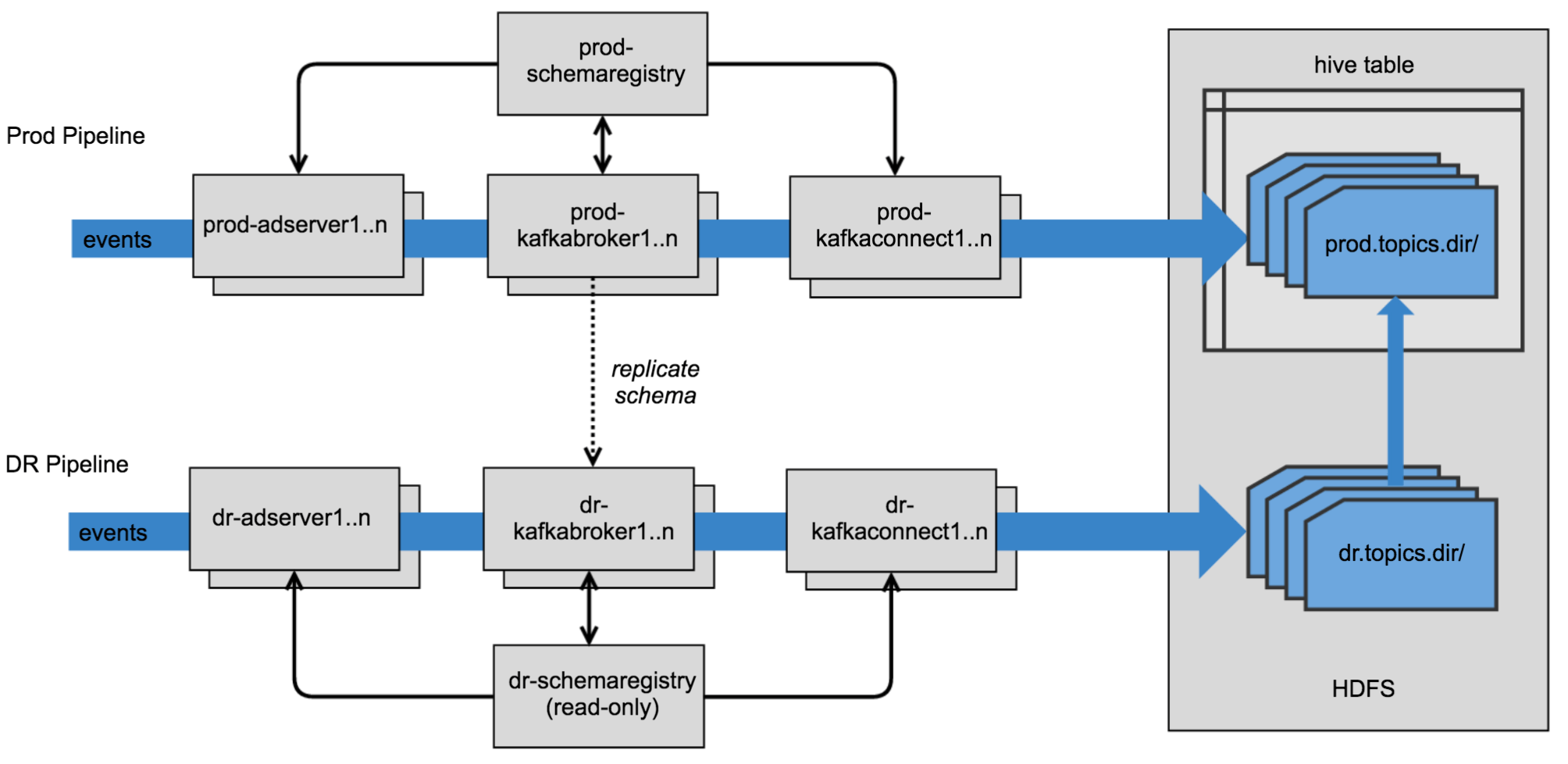
To handle failover scenarios we have a redundant Disaster Recovery (DR) pipeline operating in parallel. The DR connector is Hive integration disabled and writes Parquet files into a separate HDFS location. We have a background process that constantly moves files (except for the most recent file for each topic partition, as long as the DR pipeline is actively ingesting data) from the Parquet directory of the DR connector into the Parquet directory of the production connector. This ensures that the Hive table is not backed by two different HDFS locations. Finally, a separate read-only Schema Registry deployment is deployed into our failover environment for redundancy. See the Confluent Schema Registry Multi-DC Setup for more details.
Operationalizing the Pipeline
Tuning the Kafka Connect API Worker and Connector Configs
While moving the Kafka Connect cluster from development to production, there were a couple of worker and connector configurations that needed tuning.
For connector configs, tasks.max, flush.size, and rotate.interval.ms are very important. tasks.max is the maximum number of tasks. Each task is a dedicated thread that polls records from Kafka and writes them into HDFS, so having the tasks.max comparable with the available CPU cores is helpful for performance, and having the tasks.max comparable with the total number of topic partitions can help achieve maximum parallelism. We choose flush.size and rotate.interval.ms based on the size of the generated Parquet files. The goal is to have a file size that’s large enough to be optimal for Hive query performance based on this blog post, while not creating an extensive time interval between each write. In our case, each Parquet file is roughly 512 MB, the time between writes for each topic partition depends on the producer load of various topics, but guaranteed to be less than 17 minutes. Currently, the Hive table is partitioned by day, as defined in partition.field.name, although it would be great to have the second partition supported in the future.
Here is an example of creating a new HDFS sink connector with the proper configuration values.
Monitoring Data Pipeline
The metrics we’ve been used for monitoring the HDFS connector include CPU utilization, network utilization, Java heap size on each Kafka Connect API worker, assigned task status of the connector, as well as consumer lag of the connector for each topic partition it registered. We are also monitoring incoming Parquet files in HDFS for each topic partition. Overall, the workers are sufficiently dividing tasks evenly, but since tasks just balance topic partitions, imbalance of workload among workers could happen due to different loads on different topics. We don’t have a second connector in the production Kafka Connect cluster yet, but multiple connectors are doing well in the test environment.
While the connector is keeping up with the producer, latency is guaranteed to be less than 17 minutes and 10 minutes in average. We measure throughput while the connector is in “catching-up” mode. One 32-core Kafka Connect API worker node can achieve the HDFS writing rate of 136,000 messages per second with 75% CPU usage and roughly 225 MBps network inbound.
Operational Challenges
The HDFS connector is very stable in the production environment as long as other components of the pipeline are doing their jobs. It adjusts well when scaling the worker nodes in the Kafka Connect cluster, as well as when we dynamically update connector configurations. However, it could be fragile in the following scenarios:
- Hadoop cluster maintenance. During Hadoop cluster maintenance, we currently delete the HDFS connector from the Kafka Connect API cluster and recreate it after the maintenance, because simply pausing the HDFS connector or tasks does not work yet in this case. For the current Kafka Connect API framework, pausing connector means stopping connector, and pausing a sink task means pausing polling messages from Kafka. As for the HDFS connector, it needs to not only pause consuming from Kafka, but also a close connection from HDFS. Otherwise, some of the WAL files will not be closed properly when the network connection between the connector and HDFS is lost, and if a WAL for a topic partition is corrupted, the connector will no longer consume from that topic partition.
- Make sure the retention policy for a topic is long enough. This is obvious for all production topics since otherwise there will be data loss. In a testing environment, it is a little tricky when having a topic partition offset gap between the last offset stored in the last written file in HDFS and the first message offset in Kafka. In that case, the connector will keep looking for the next offset forever. If we want to keep the existing Parquet files in HDFS, we need to do the following: delete the current connector, move the old Parquet files to a different HDFS directory, remove all the WAL logs, create a new HDFS connector to start consuming from fresh, wait until every topic partition has a file written, and then move the old Parquet files back.
Summary
We built a robust data pipeline with production readiness from Ad Servers to HDFS using Kafka, the Kafka Connect API, and Schema Registry. Despite some minor limitations, we are very satisfied with the performance of the Confluent HDFS Sink Connector as well as the responsive community. It has greatly reduced our turnaround time, and the pipeline is certainly reusable for our future use cases. With the benefits provided by the Kafka Connect API – mainly making things easier to implement and configure – we are also in the process of developing more connectors for our other internal systems.
This is a guest blog post from Alexandra Wang, Software Engineer, Pandora Media. You can connect with her on LinkedIn. Also special thanks to Lawrence Weikum and Stu Thompson as contributors of the work in this post. You can also find this post on Pandora’s blog.
References
Avez-vous aimé cet article de blog ? Partagez-le !
Abonnez-vous au blog Confluent



From Dumb Pipes to a Smart Data Plane: Introducing Schema IDs in Apache Kafka® Headers
Confluent’s Schema IDs in headers transform Kafka from "dumb pipes" to a "smart data plane." By moving metadata out of payloads, teams can schematize topics without breaking legacy apps or requiring big-bang migrations. This unlocks governed, AI-ready data for Flink and lakehouses with ease.


Queues for Apache Kafka® Is Here: Your Guide to Getting Started in Confluent
Confluent announces the General Availability of Queues for Kafka on Confluent Cloud and Confluent Platform with Apache Kafka 4.2. This production-ready feature brings native queue semantics to Kafka through KIP-932, enabling organizations to consolidate streaming and queuing infrastructure while...