[Virtual Event] Agentic AI Streamposium: Learn to Build Real-Time AI Agents & Apps | Register
Adopt Data Streaming with The Definitive Guide
Enabling data in motion within an organization involves much more than simply setting up a Confluent cluster, piping in a few data sources, and writing a set of streaming applications. You need to consider how to ensure reliability of your applications, how to enforce data security, how to integrate delivery pipelines, and how your organization will develop and evolve governance policies. It’s difficult to know where to start.
Whether you’re a developer or architect, a platform owner or an executive, you must consider different efforts when moving workloads to production depending on whether those workloads are simple or mission critical—and how these roll up into a sound enterprise-wide data strategy. While there is no one-size-fits-all solution for data streaming systems across industries, there are logical, broad sets of knowledge and actions required to be successful. For example, understanding event-driven designs and patterns, shifting to a strategy on how to deploy and operate clusters, and ensuring security, operational, and governance processes along the way.
When you are just starting on this journey, it is not always obvious what concerns need to be addressed and in what order. To help organize the knowledge, actions required, and resources available to you, we’re proud to announce the launch of “Setting Data in Motion: The Definitive Guide to Adopting Confluent.”
This guide was written by our professional services team—architects, engineers, and managers who have worked in the field, developing data streaming solutions with hundreds of our customers. We have worked with companies including the largest global enterprises and the most innovative digital natives at various stages of maturity with Confluent and Apache Kafka®; some early in their journey focused on initial interest and proof of concepts, to more mature organizations with event streaming at the heart of their business.
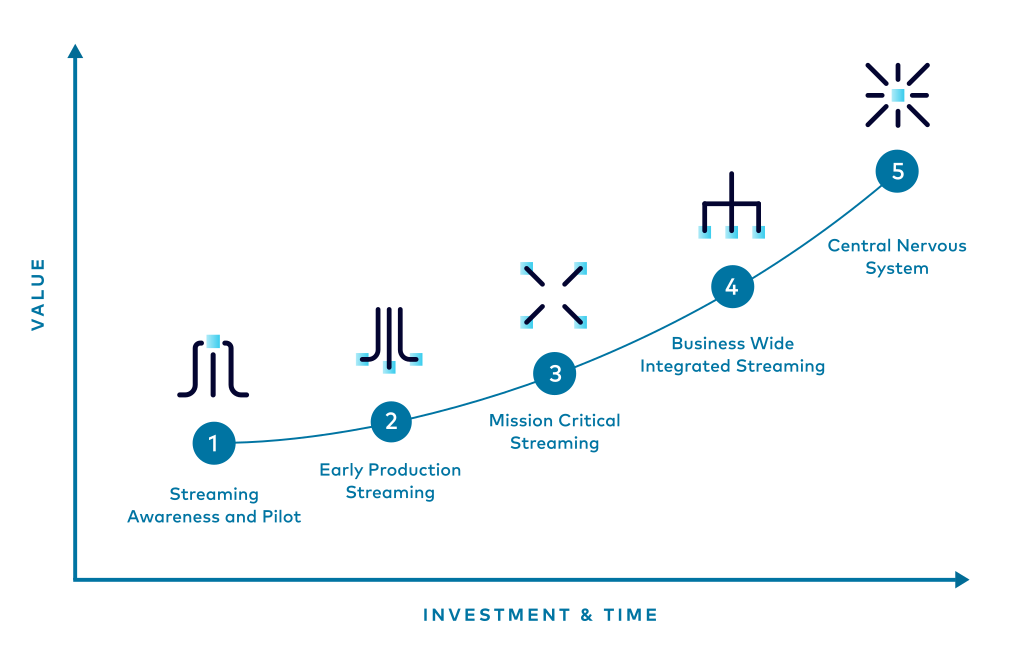
The streaming maturity model
We have distilled the knowledge from this experience into a set of topics, or recipes, grouped into major themes:
- Event Streaming Solution – Introduces you to the topics that make up the fundamentals of event streaming in Confluent Platform and Confluent Cloud
- Architecture and Strategy – Outlines the steps necessary to design enterprise-wide event-driven application architectures
- Cluster Strategy – Helps you work out how to deploy an event streaming platform to suit your organization
- Infrastructure and Hosting – Looks at the infrastructure and mechanics necessary to access Confluent clusters in both on-premises and cloud environments
- Platform Security – Walks you through the details of securing access to a Confluent deployment
- Data Security and Privacy – Helps you work out how to grant access to the data that lives in your Confluent cluster to authorized parties only
- Process and Governance – Helps you define and manage process controls around a streaming platform and its applications
- Scaling and Automation – Helps you define a strategy for managing the deployment and scaling of Confluent using automation
- Operational Monitoring – Focuses on what you need to do to gain insight into the performance and behavior of your streaming platform and applications
- Operational Performance – Deals with defining and delivering expected throughput, latency, durability, and availability in a Confluent installation
Each topic addresses questions that we have repeatedly faced during implementation programs:
- What problem does it solve?
- When should you do it?
- Who is involved in delivery?
- What prerequisites need to be addressed?
- What do you need to do?
- Where can you find supporting information?
This guide is designed to:
- Help platform owners and project managers put together a program of work, by defining what needs to be done, in what order, and by whom in the journey of maturing their event streaming capabilities
- Help architects and engineers understand what needs to be done to ensure that they have adequately addressed the needs of the topic at hand, and to point them to the information that they need to get the job done
The guide is not intended to be read end to end, but rather as a reference for you to dive into throughout your journey. This makes it a valuable resource, regardless of whether you are just starting out, or if you are consolidating multiple clusters as part of a data mesh strategy.
We hope this book helps you to successfully implement and grow event streaming within your business at each stage of platform adoption.
Avez-vous aimé cet article de blog ? Partagez-le !
Abonnez-vous au blog Confluent


Focal Systems: Boosting Store Performance with an AI Retail Operating System and Real-Time Data
Discover how Focal Systems uses computer vision, AI, and data streaming to improve retail store performance, shelf availability, and real-time inventory accuracy.


Thunai Automates Customer Support with AI Agents and Data Streaming
Learn how Thunai uses real-time data streaming to power agentic AI, achieving 70–80% L1 support deflection and cutting resolution time from hours to minutes.