[Virtual Event] Agentic AI Streamposium: Learn to Build Real-Time AI Agents & Apps | Register
The 2017 Apache Kafka Survey: Streaming Data on the Rise
In Q1, Confluent conducted a survey of the Apache Kafka® community and those using streaming platforms to learn about their application of streaming data. This is our second execution of this survey, so we do have some year over year information. With respondents from over 350 organizations across 47 countries, we’re feeling like this is a solid representation of where streaming data is today, and can be a valuable benchmark for understanding change in the data infrastructure market.
This blog introduces some key findings, or you can download the full report here.
86% of respondents are increasing their Kafka use, 20% by a lot
What will be no surprise to those who are active in the Kafka community: 86% of respondents are increasing their Kafka use, and 20% by a lot. At Confluent, we see this traction at conferences, meet-ups, in our Slack community, activity volume in online communities, and just the general excitement and stories when Kafka people get together. It’s hard to put your finger on that one thing that says a technology is creating a movement; it sure seems like that’s what’s happening here.
Over Half of Respondents are Using Kafka in the Public Cloud
It would be impossible for a trend with this growth to occur without making contact with the other huge trend in data infrastructure – the cloud! The survey indicates large organizations are moving to the public cloud with their Kafka clusters. In fact, over half of the survey respondents are using Kafka in the public cloud. Kafka can be used as a pipe to help companies move their data from on-premises systems to the cloud of their choice, eliminating vendor lock-in and assisting with the large amount of effort and coordination it takes to make that shift.

Apache Kafka: Not Just for Pub-Sub Anymore
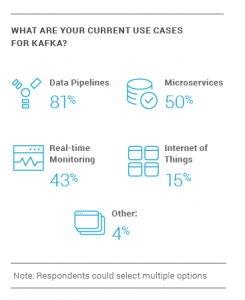
We’re also seeing companies use Kafka for far more than publish-subscribe. The use cases for Kafka have grown to include microservices, IoT, and monitoring to name a few dramatic increases from the previous year. From those surveyed, two-thirds (66%) use Kafka for stream processing and three out of five (60%) use it for data integration. The most common use case for Kafka is data pipelines (81%), while half (50%) are already using it for microservices. As companies are adopting microservices for their distributed architectures, Kafka is here to help.
Helpful tip: If you’re looking into microservices and want some general best practices, check out our resident expert Ben Stopford’s 3-part series here.
Microservices, Meet the Kafka Streams API
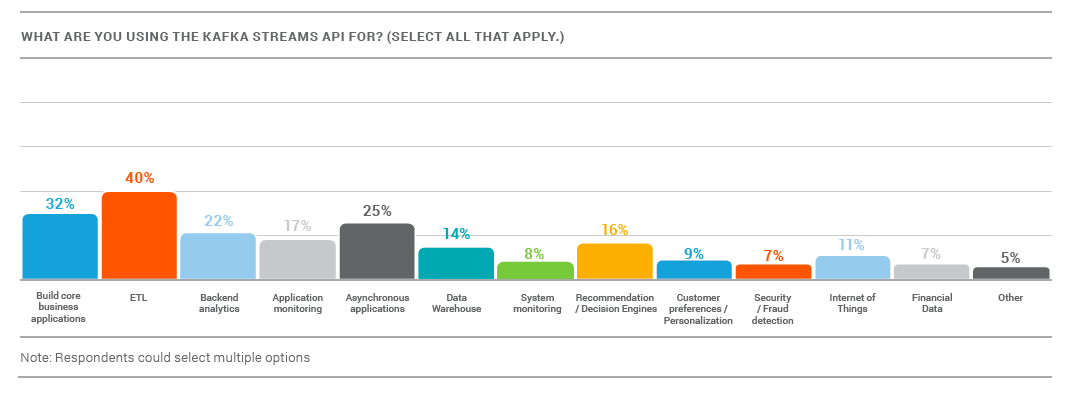
If you’re using microservices to build applications, it is made much easier with the Kafka Streams API as developers have the ability to work with data in-flight. Of the organizations that have microservices, already 28% use the Kafka Streams API to build them. The Kafka Streams API is most frequently utilized by developers (85%), but architects (48%) and application teams (43%) also use it. Introduced last year, the Kafka Streams API integrates into your streaming application to build and execute powerful stream processing functions, without needing to set up and run separate infrastructure. Despite its recency, most (89%) organizations are already familiar with the Kafka Streams API. The most common uses for the Kafka Streams API are ETL (40%), building core business applications (32%), and asynchronous applications (25%).
Kafka Engineers are in Demand
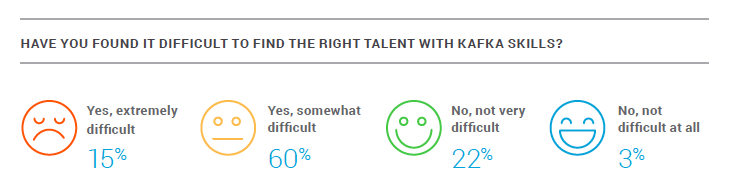
With the growing adoption of Kafka, one conclusion worth noting is the lack of ability to hire Kafka talent. While we think Kafka engineers are generally pretty smart ( 🙂 ) turns out they’re also hard to hire. 75% of respondents said they are having difficulty finding Kafka trained engineers. We recently introduced a Kafka certification to help with that problem and also offer training to help developers get up to speed on all things Kafka.
Join us at Kafka Summit NYC!
With these results and the growing use of Kafka and streaming platforms, we’re even more excited about Kafka Summit coming up next week. It’s the best place to learn from companies large and small doing some incredible work with Kafka. It’s not too late to register! We hope to see you there.
Avez-vous aimé cet article de blog ? Partagez-le !
Abonnez-vous au blog Confluent



From Dumb Pipes to a Smart Data Plane: Introducing Schema IDs in Apache Kafka® Headers
Confluent’s Schema IDs in headers transform Kafka from "dumb pipes" to a "smart data plane." By moving metadata out of payloads, teams can schematize topics without breaking legacy apps or requiring big-bang migrations. This unlocks governed, AI-ready data for Flink and lakehouses with ease.


Queues for Apache Kafka® Is Here: Your Guide to Getting Started in Confluent
Confluent announces the General Availability of Queues for Kafka on Confluent Cloud and Confluent Platform with Apache Kafka 4.2. This production-ready feature brings native queue semantics to Kafka through KIP-932, enabling organizations to consolidate streaming and queuing infrastructure while...